Part II: Pragmatic Solutions and Best Practices
Save time, reduce errors, and work more efficiently in teams
September 8, 2025
Welcome to Part II

Pragmatic Solutions and Best Practices
The reality we all know
- Tight timelines, changing specs, handovers
- Old scripts reused under pressure
- “I’ll clean this later” — later never comes
- Result: time loss, bugs, stress

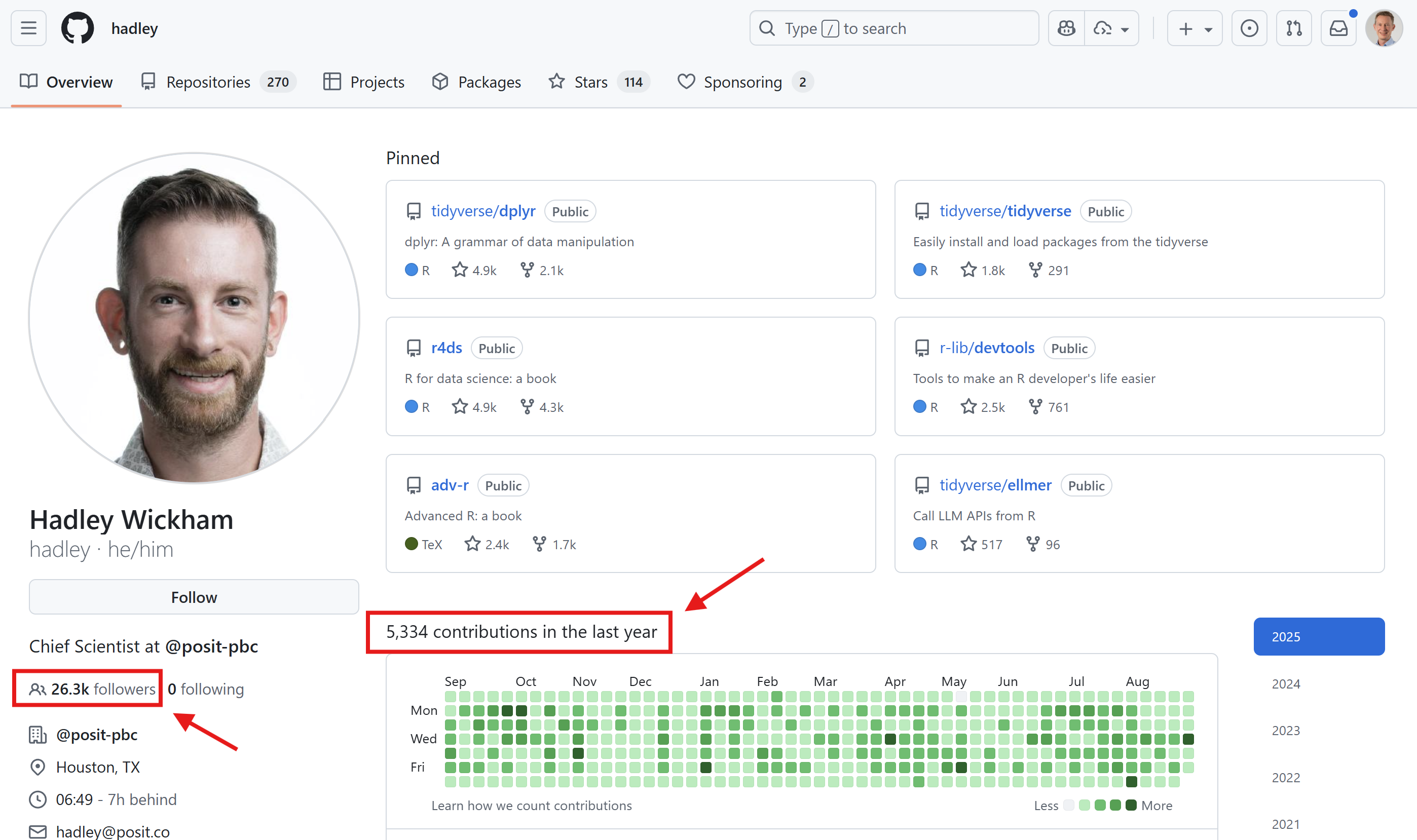
GitHub From the Beginning

GitHub tells the whole story of your project
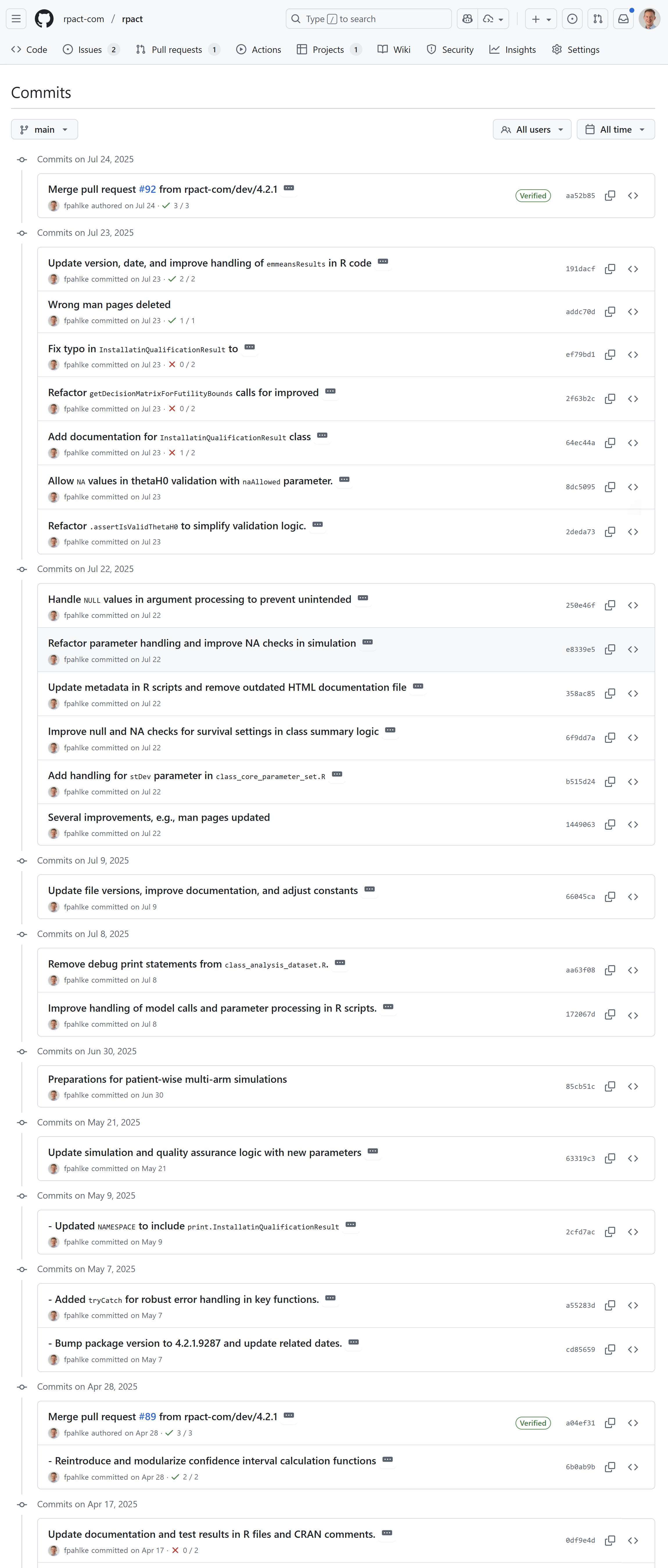
GitHub as your business card
- GitHub as your business card and career showcase
- Who would you hire?
Fictive example: Clinical trial analysis

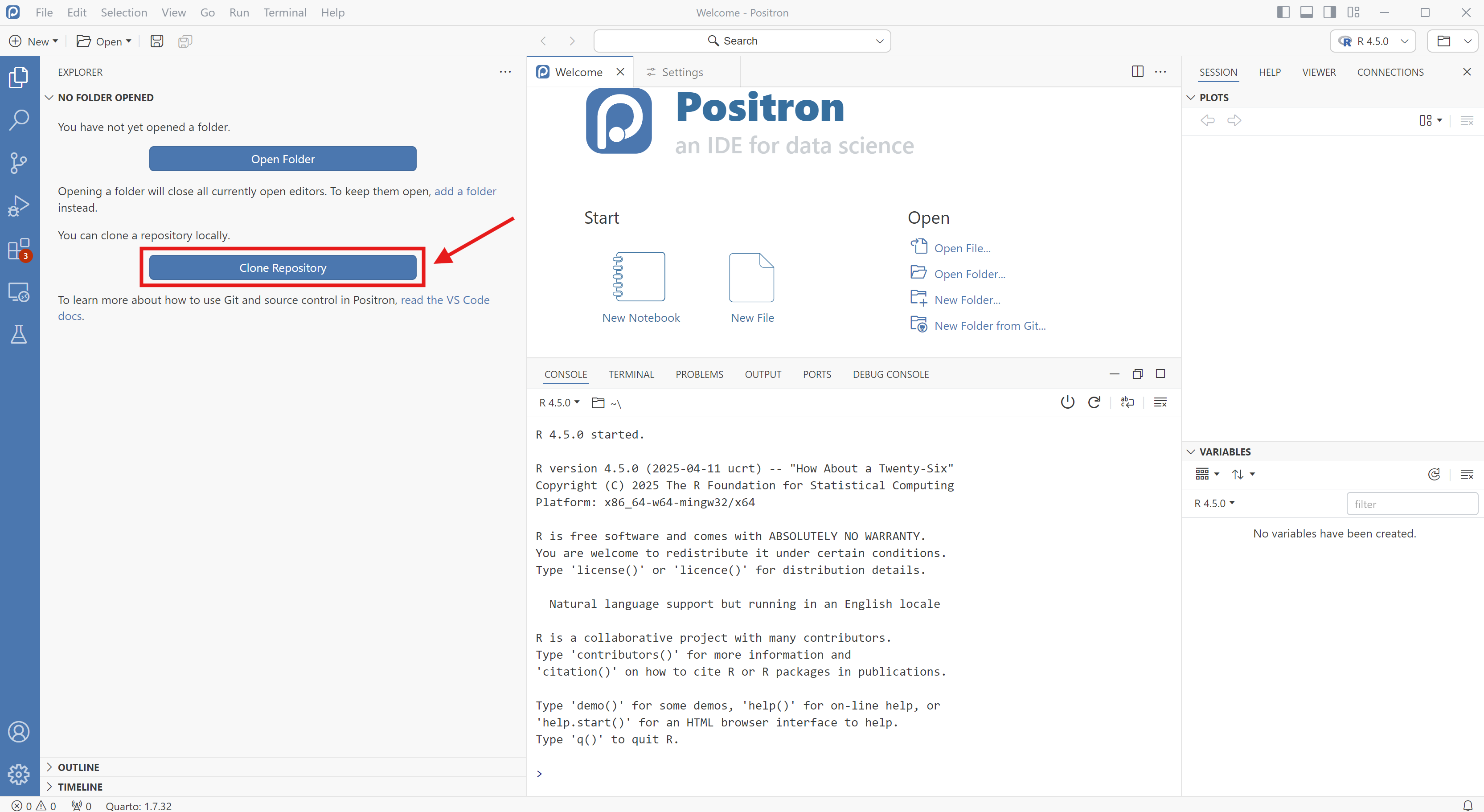
Let’s use GitHub
Create a new repository on GitHub, clone it to your local machine, and add a README.md file with a brief description of your project.

TortoiseGit
Windows context menu for GitHub: TortoiseGit

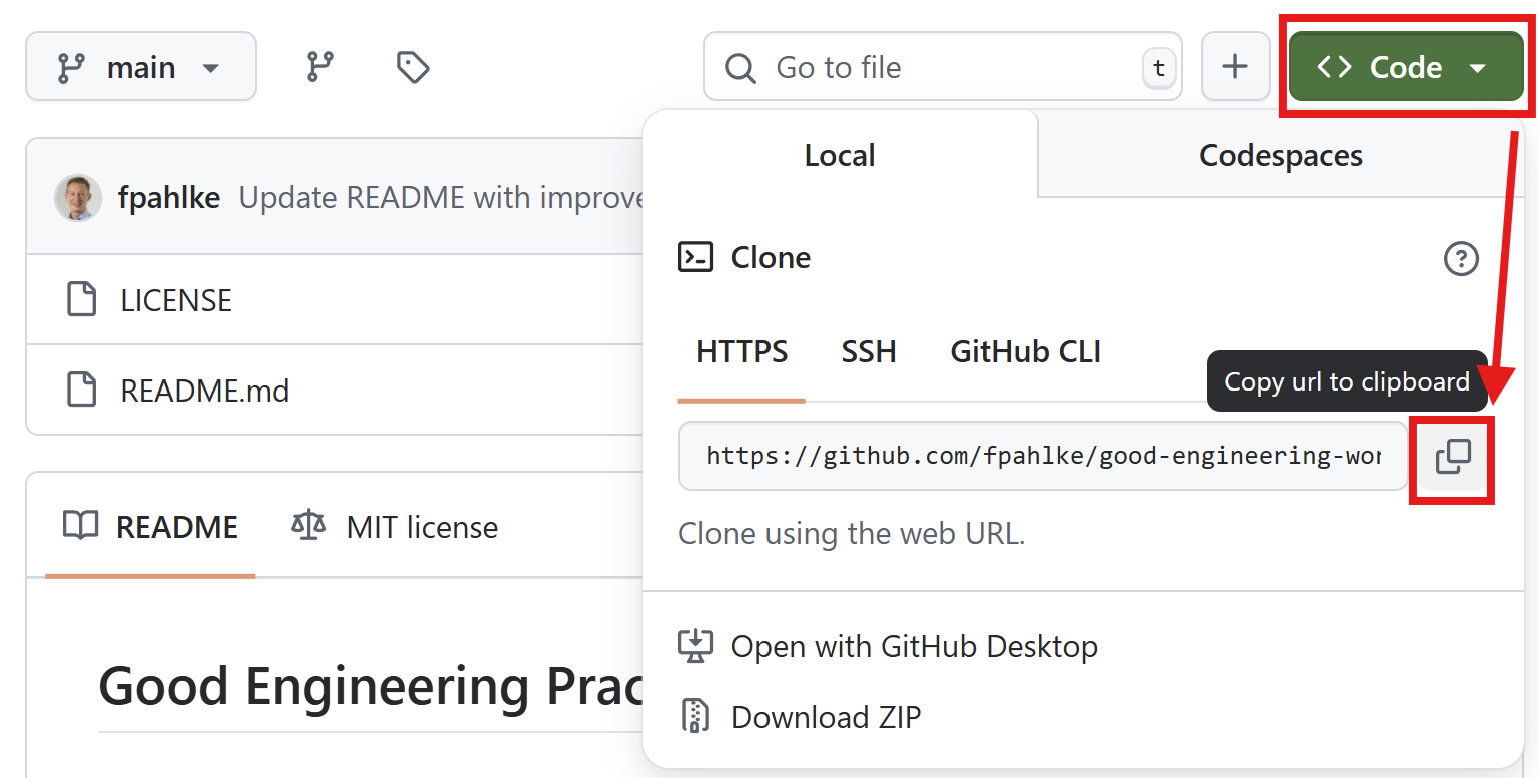

GitHub Desktop
GitHub Desktop App
Other GitHub Apps
Many other ways to use GitHub: Eclipse, Positron, VS Code, RStudio, …
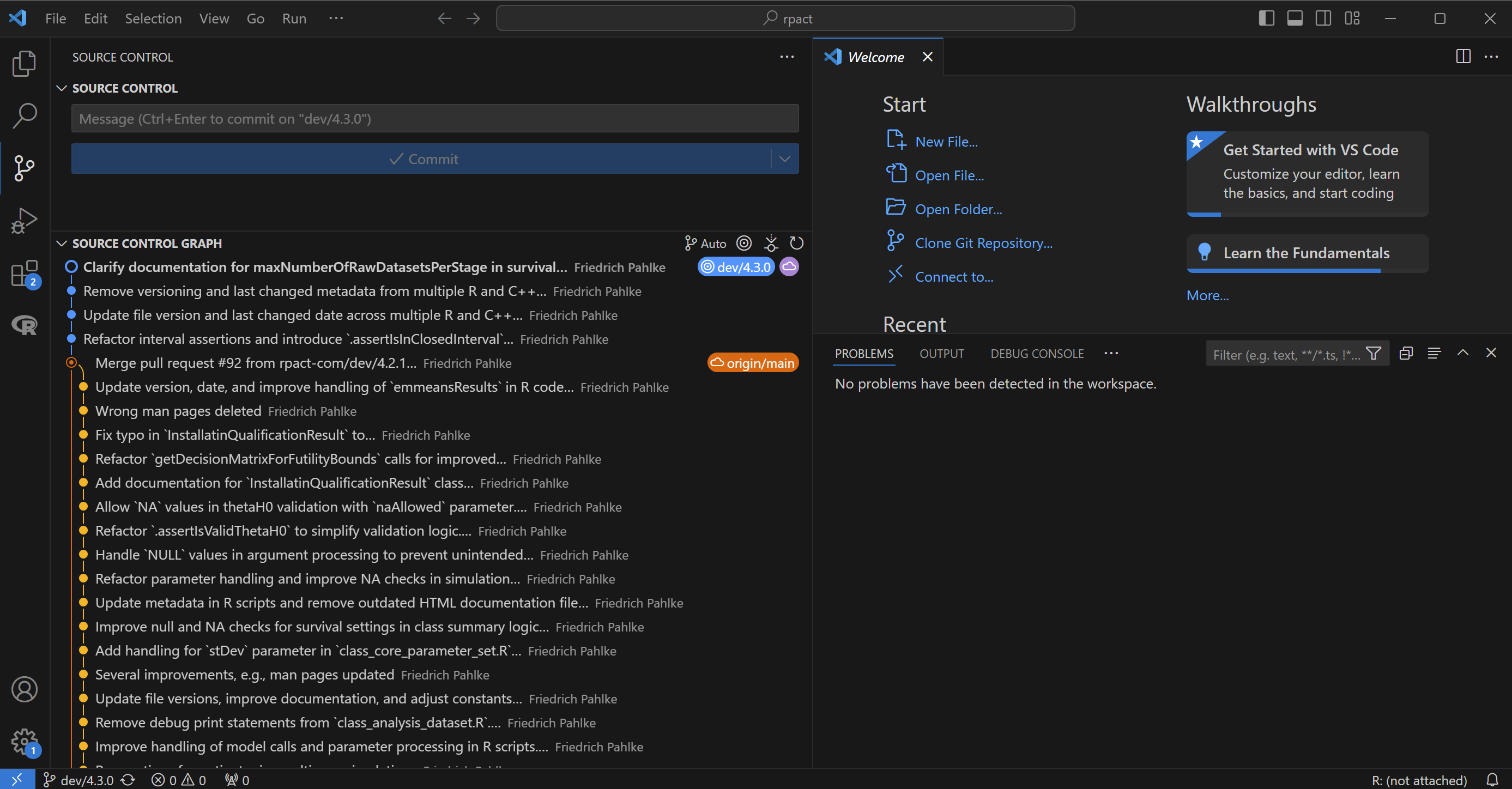
Let’s create the two branches

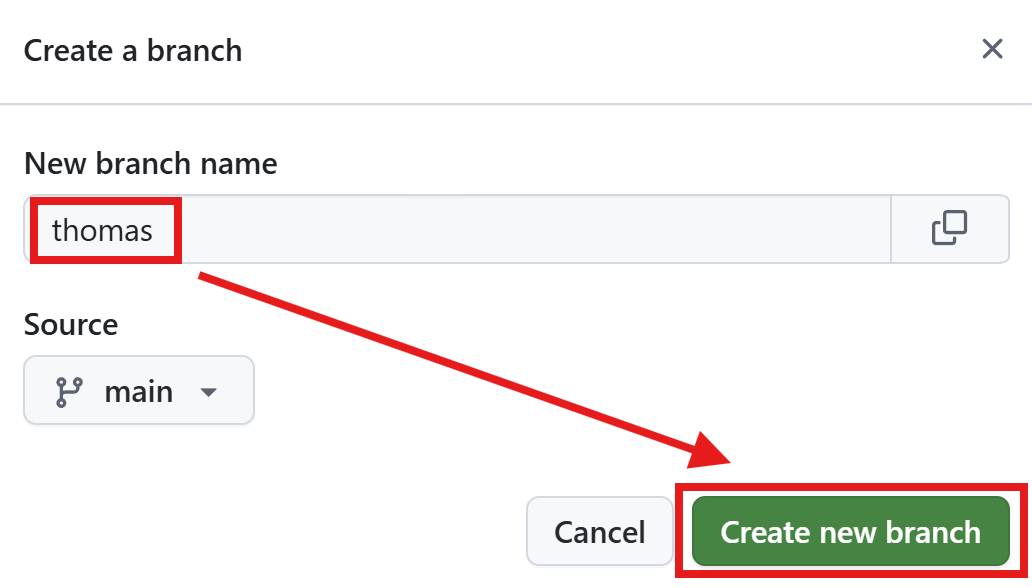
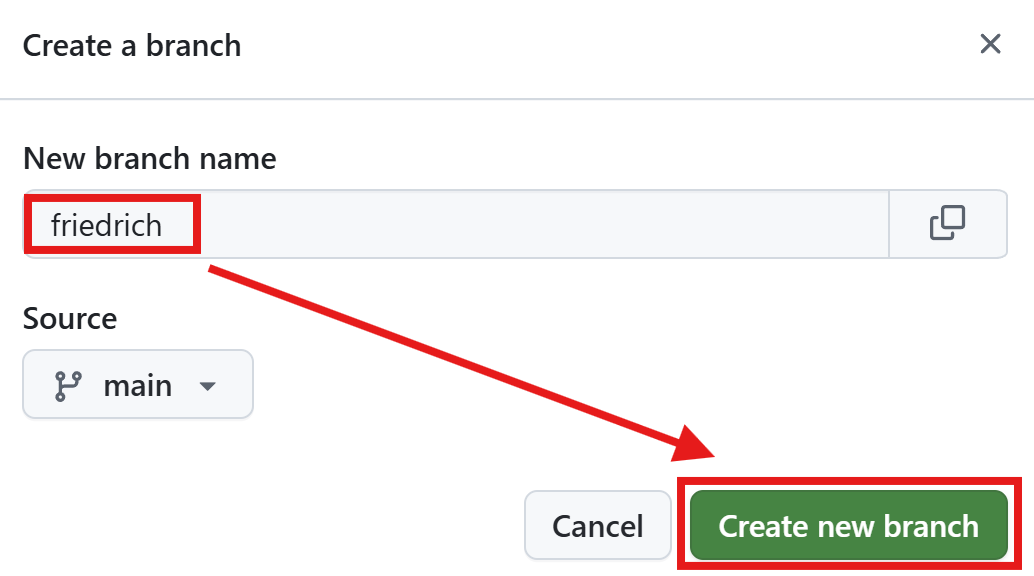
Branches
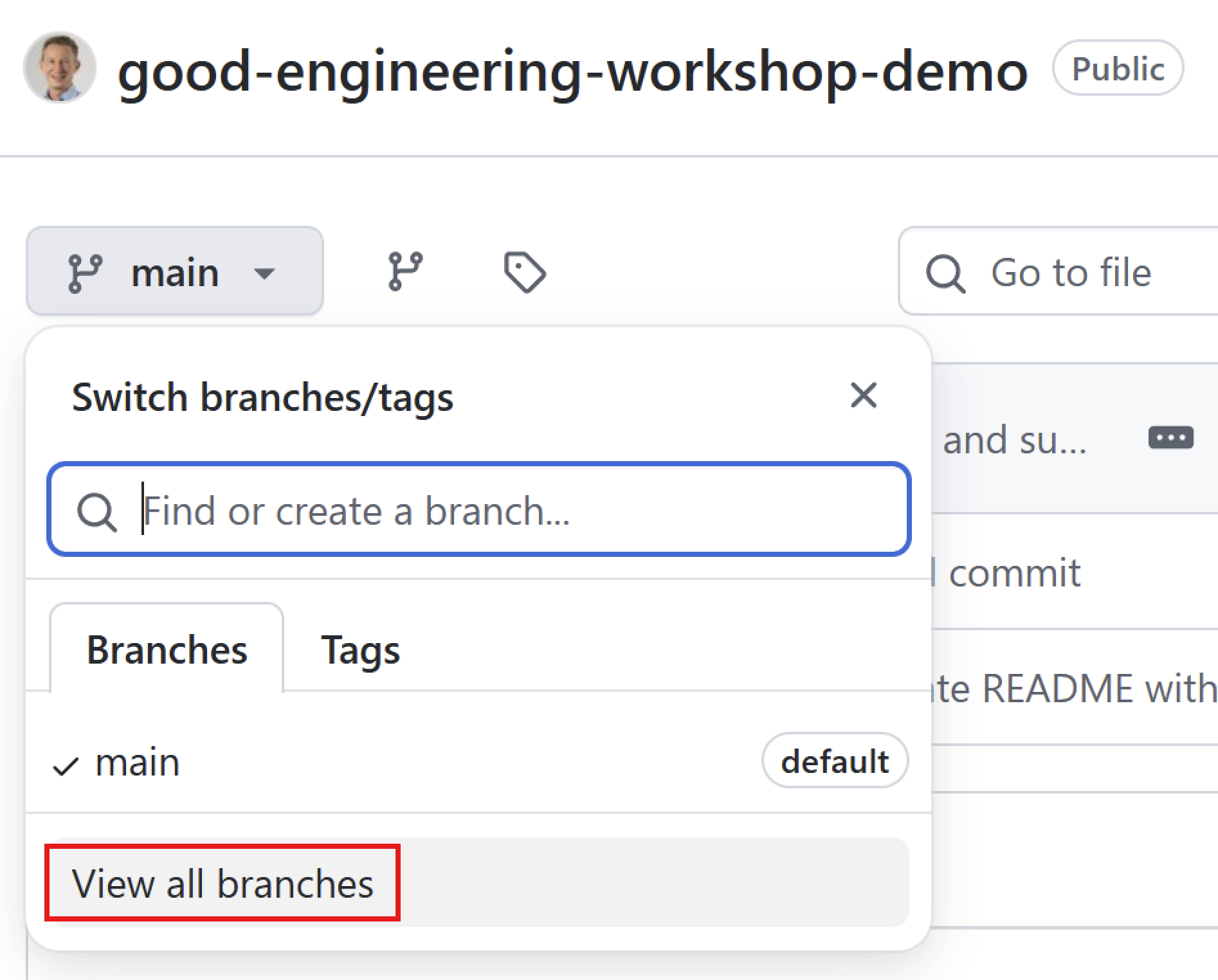
github.com/fpahlke/good-engineering-workshop-demo/branche
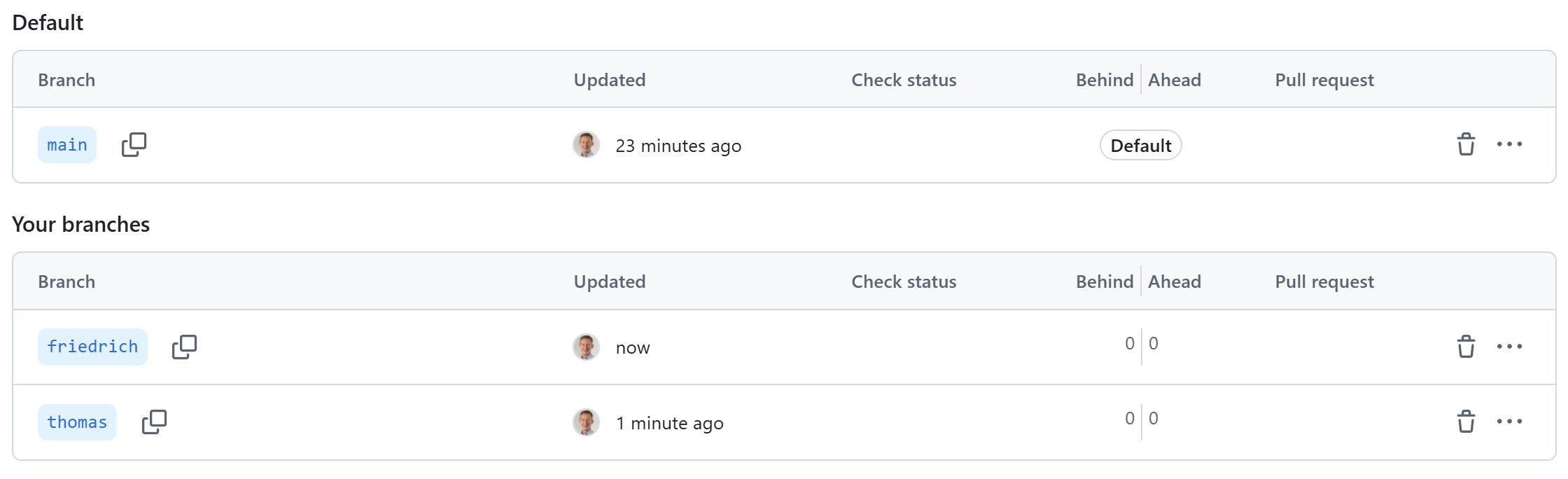
GitHub branches overview page
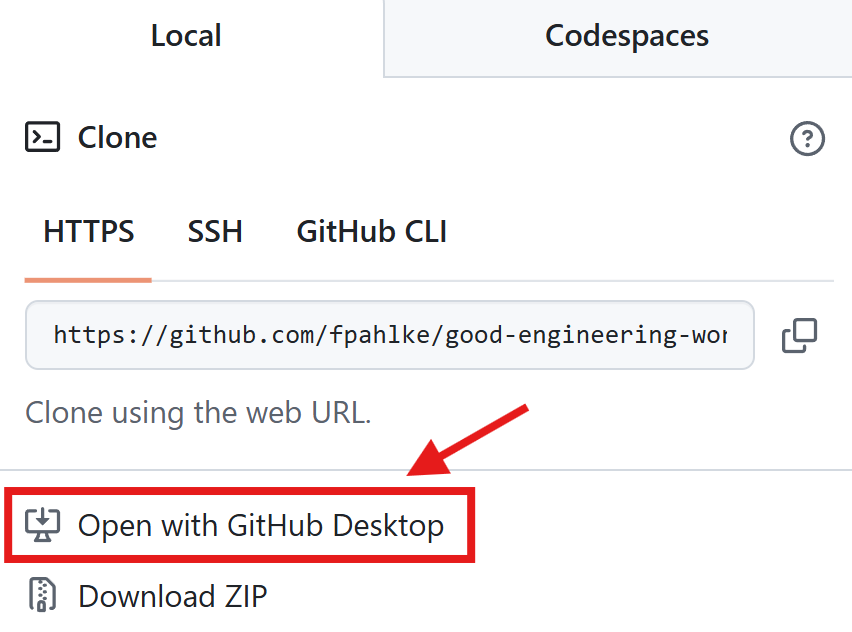
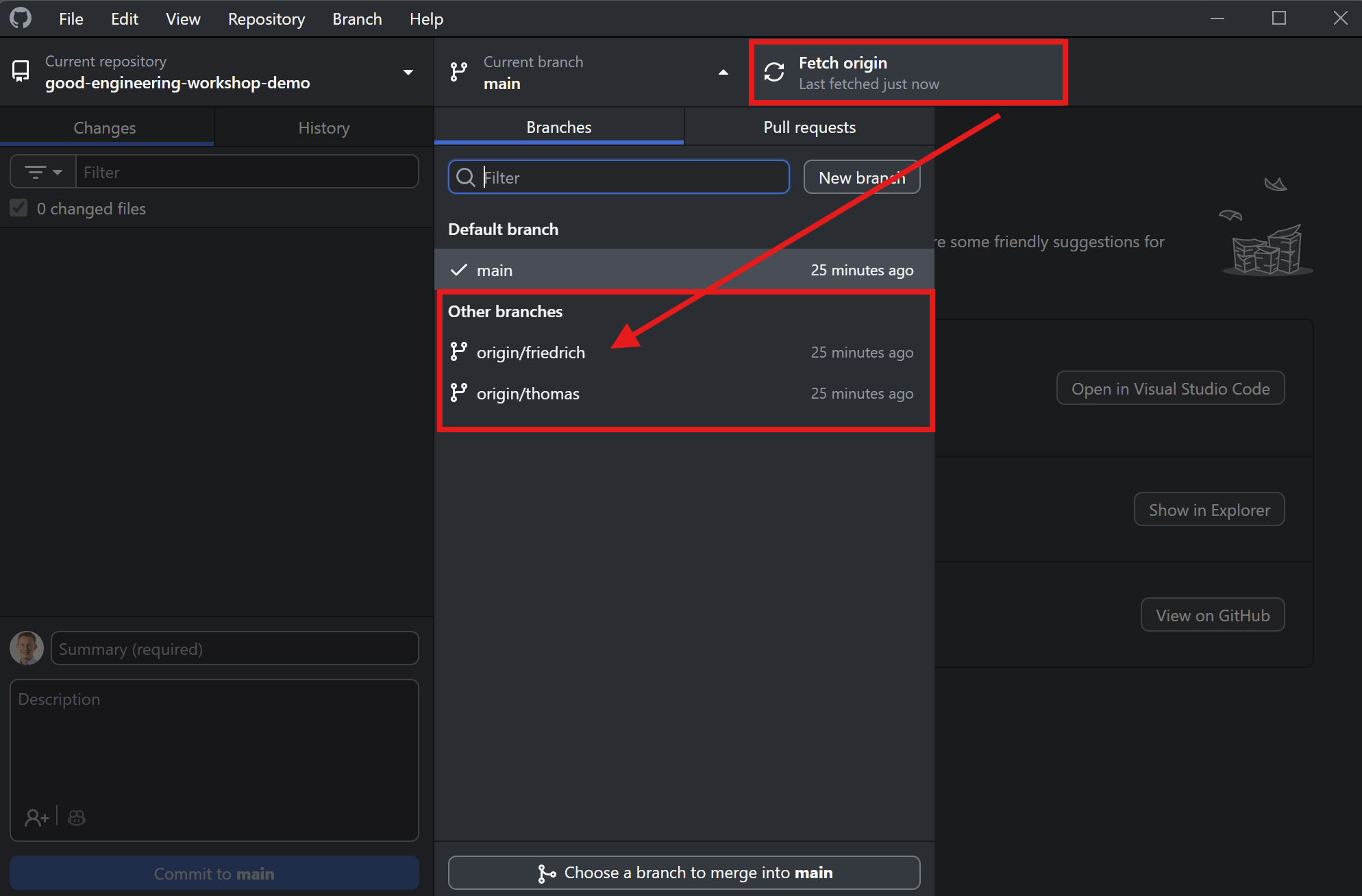
Let’s clone the repository with GitHub Desktop
Fetch origin (update local information) and then select branch friedrich.
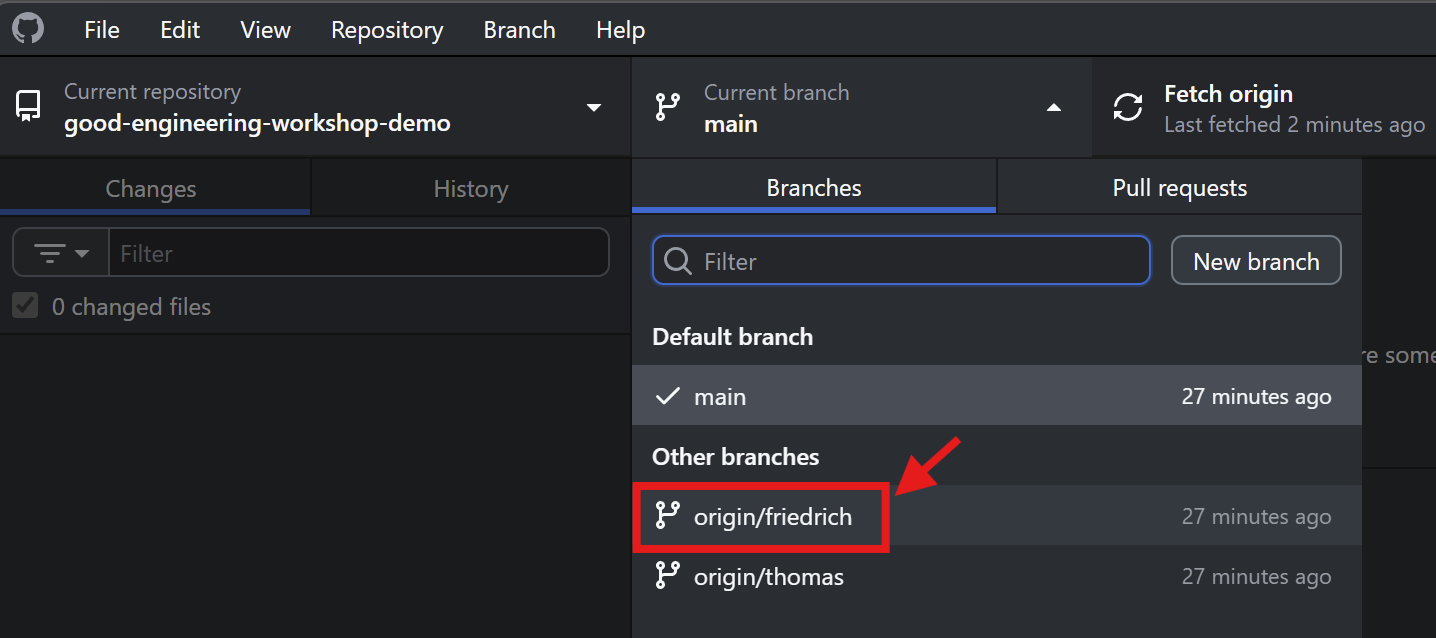
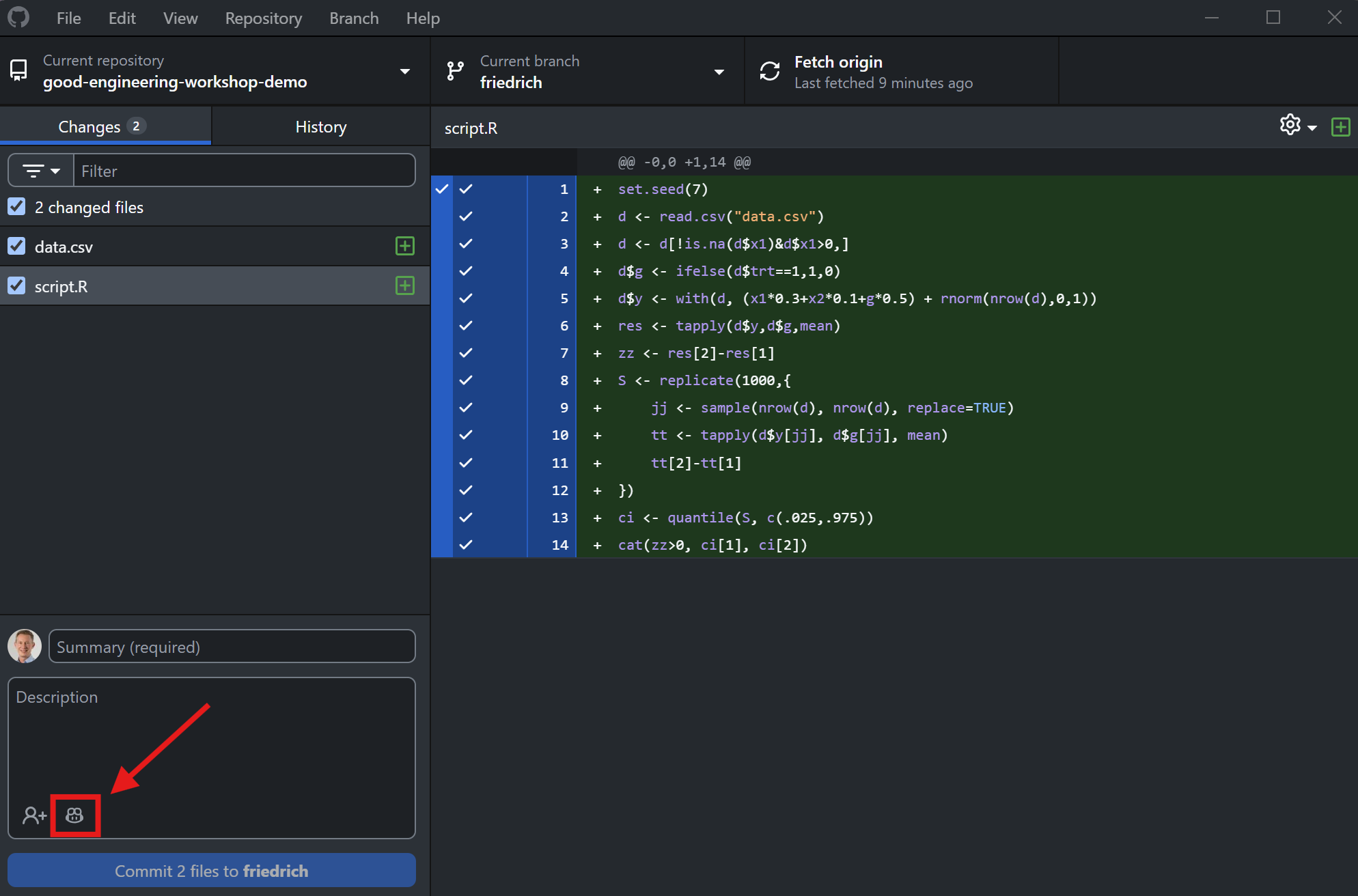
Add a new R script and data file
Add a new R script and data file
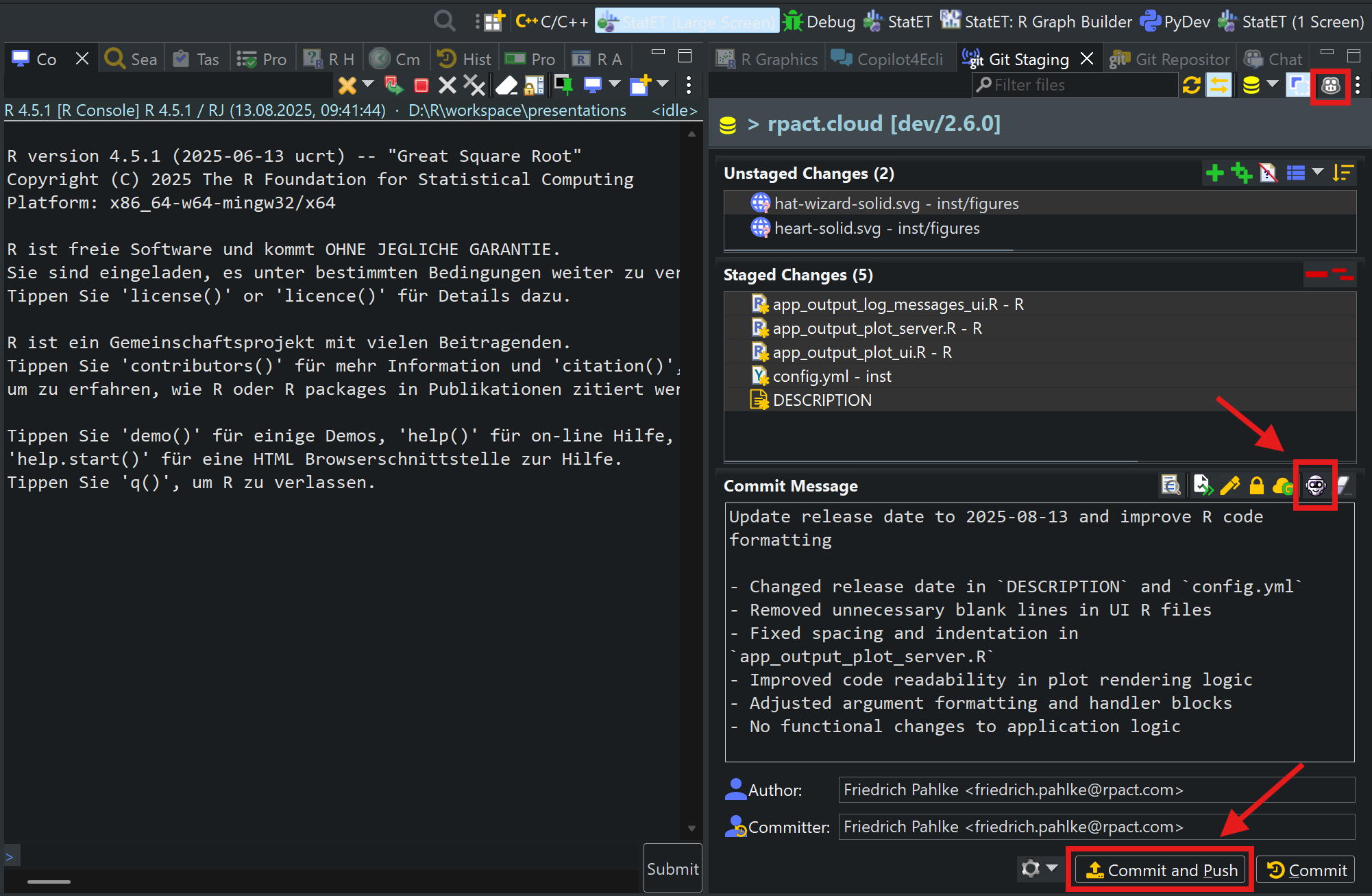
Use Copilot to write the commit message
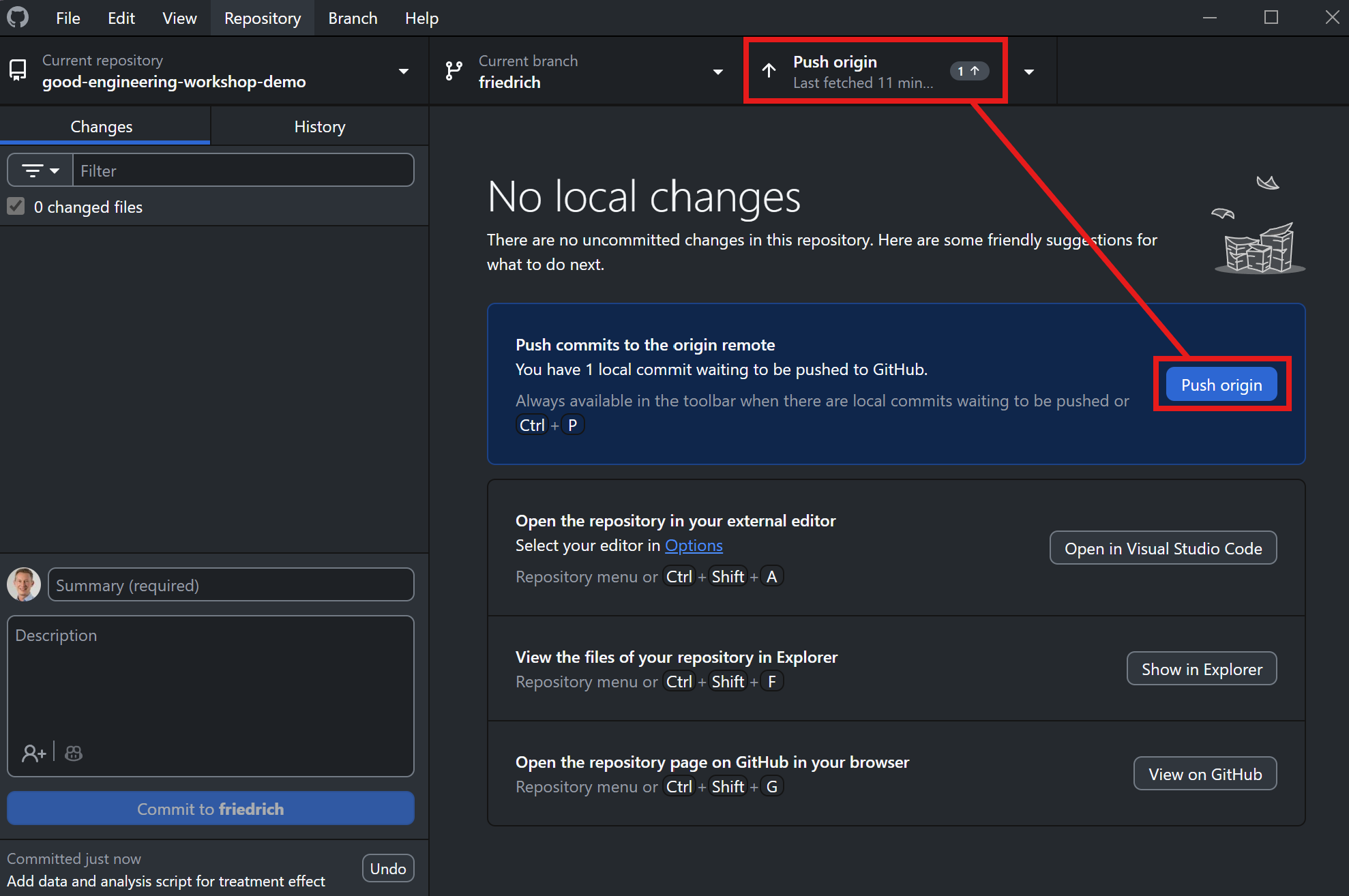
Push the changes to GitHub
Push the changes to GitHub
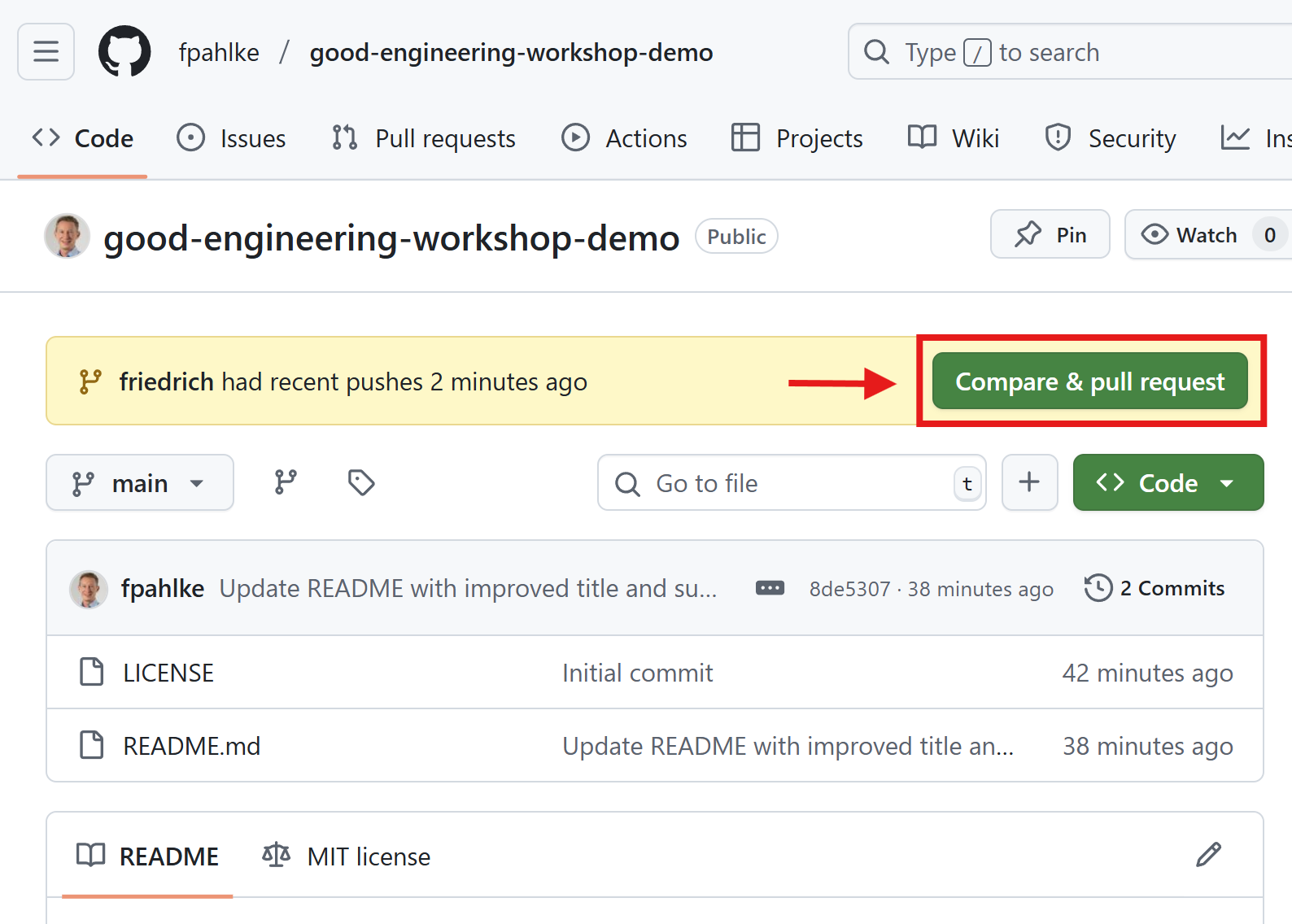
Create a pull request
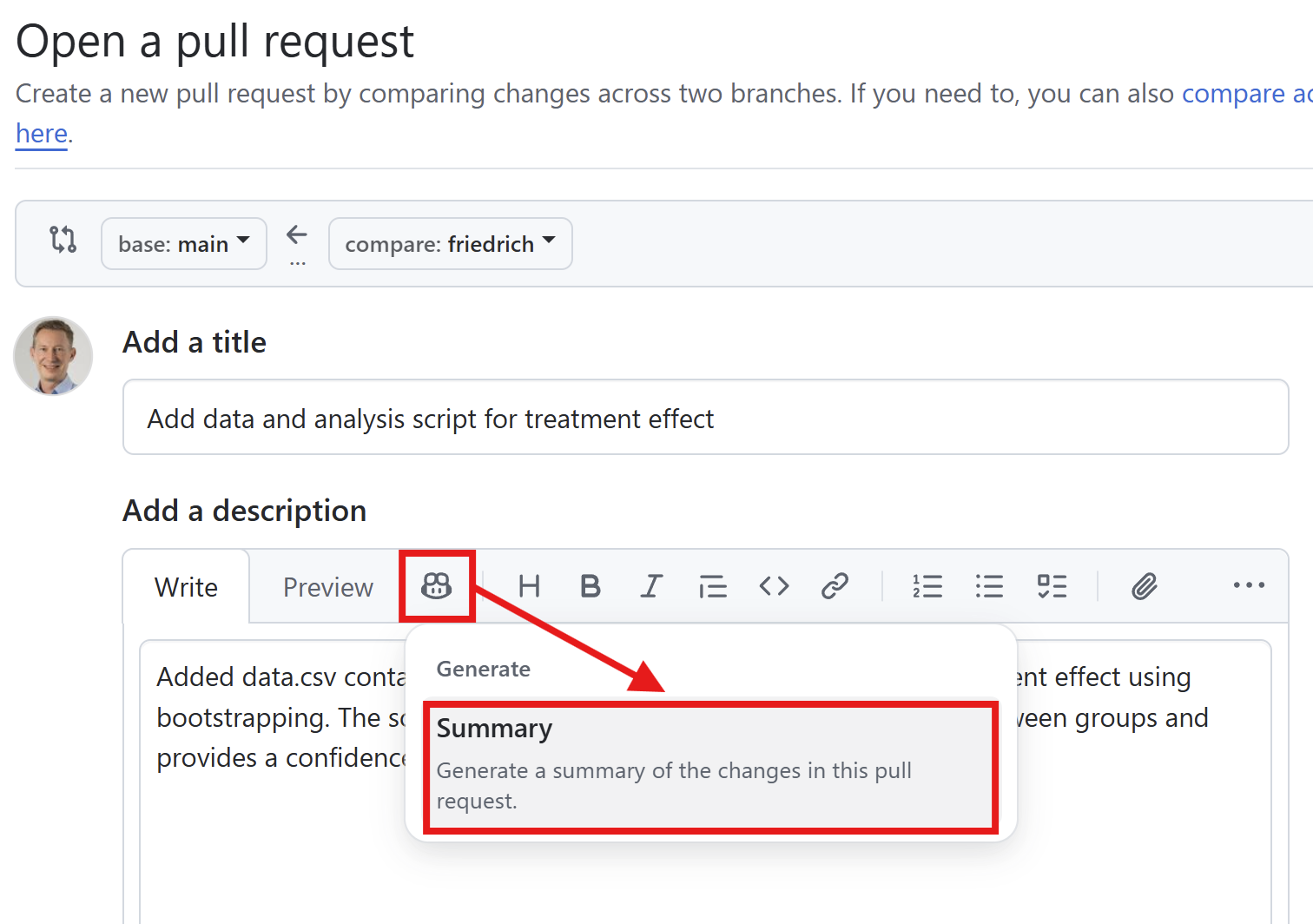
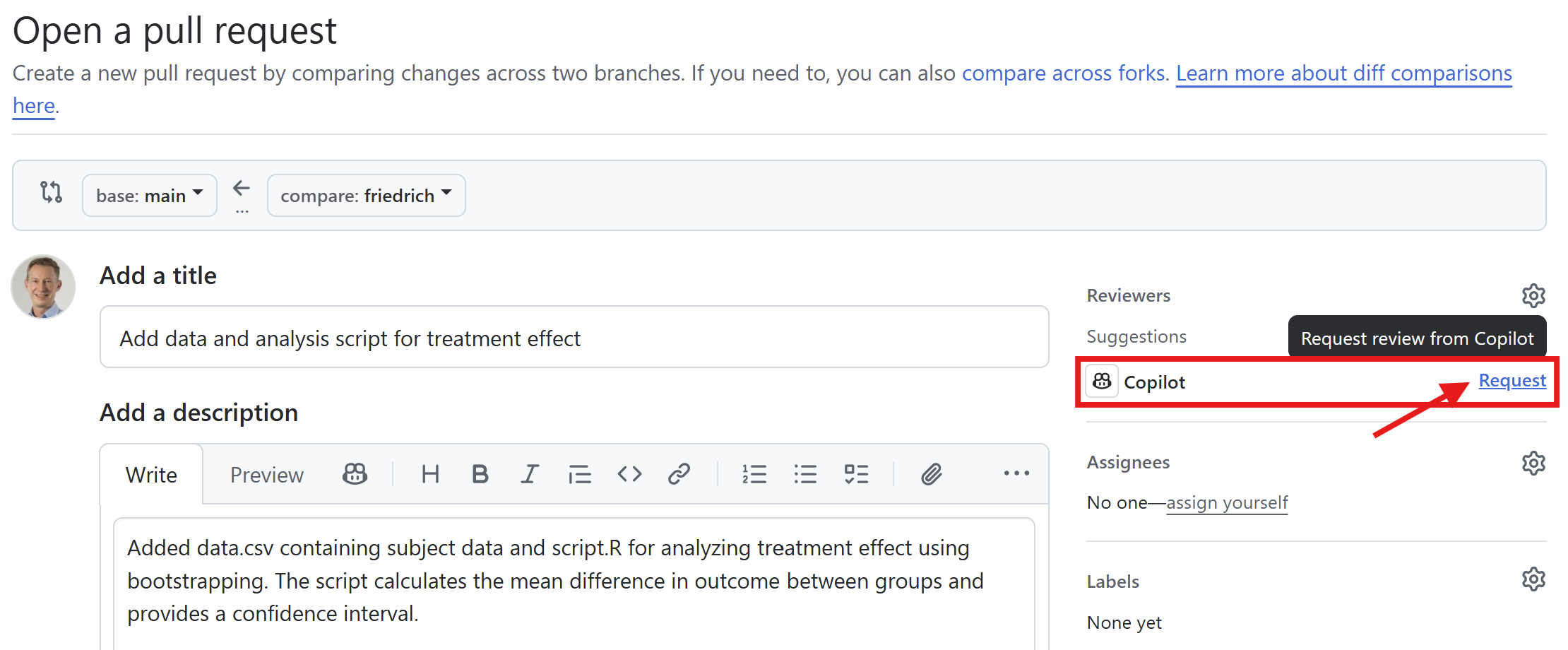
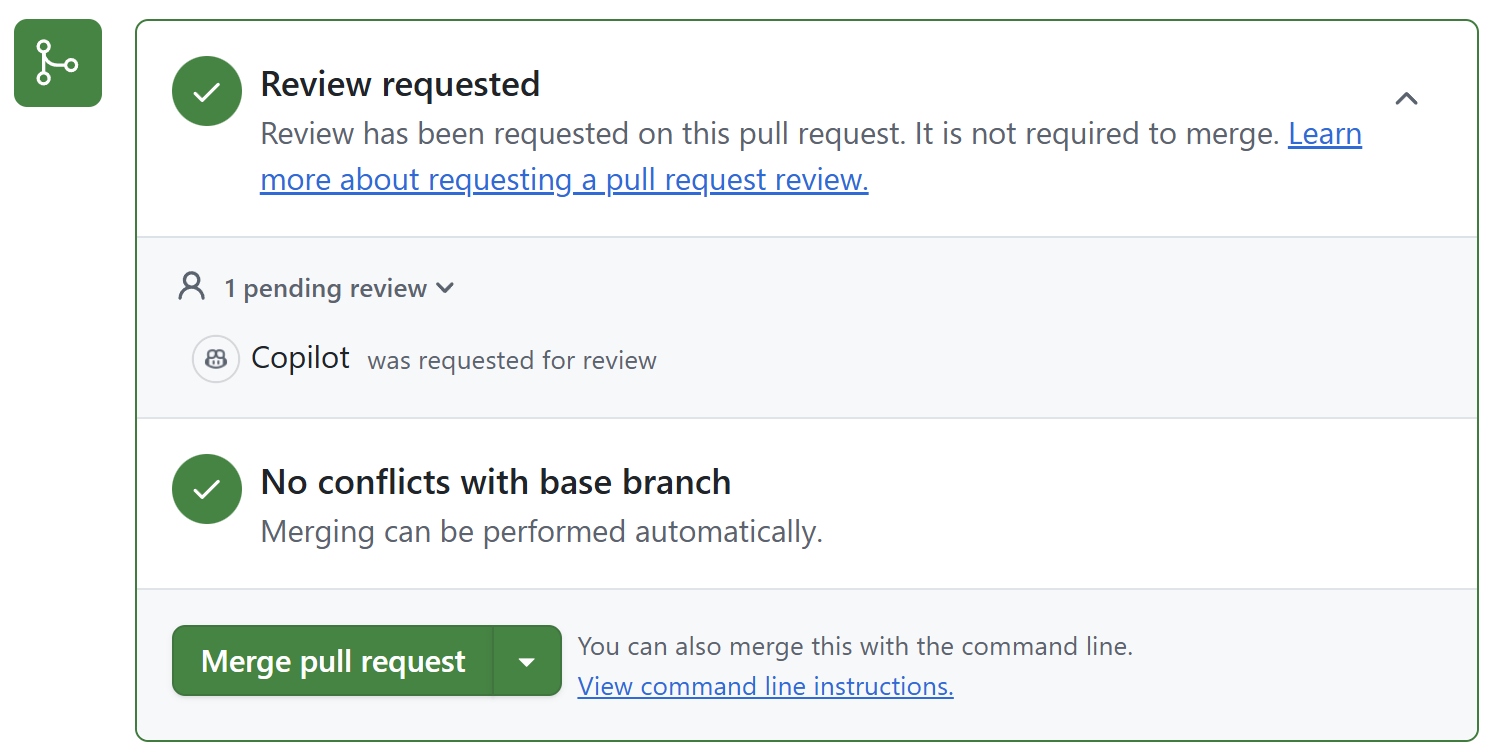
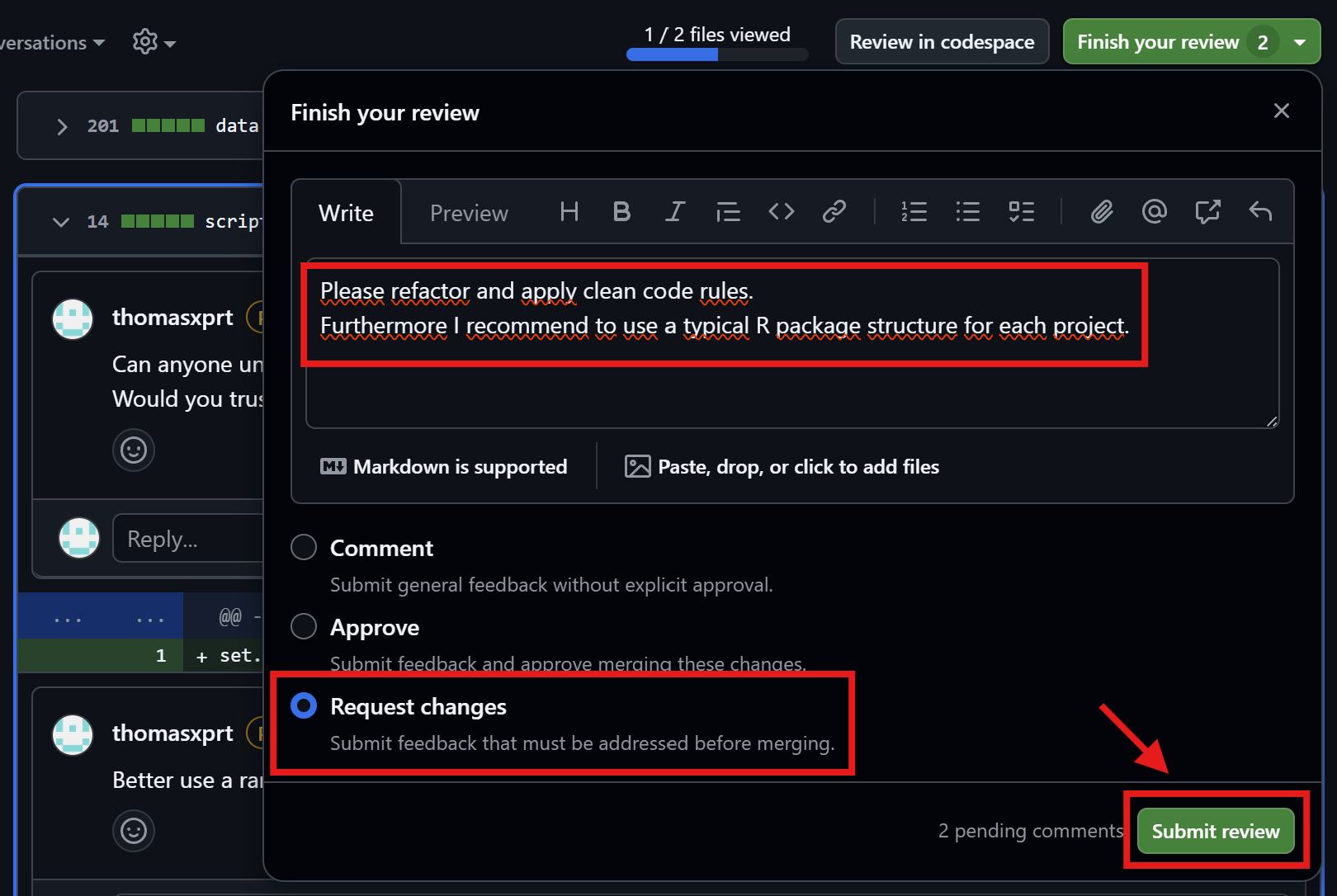
Use Copilot for the pull request description and review of the changes.
Add additional reviewers
First invite Thomas as collaborator.
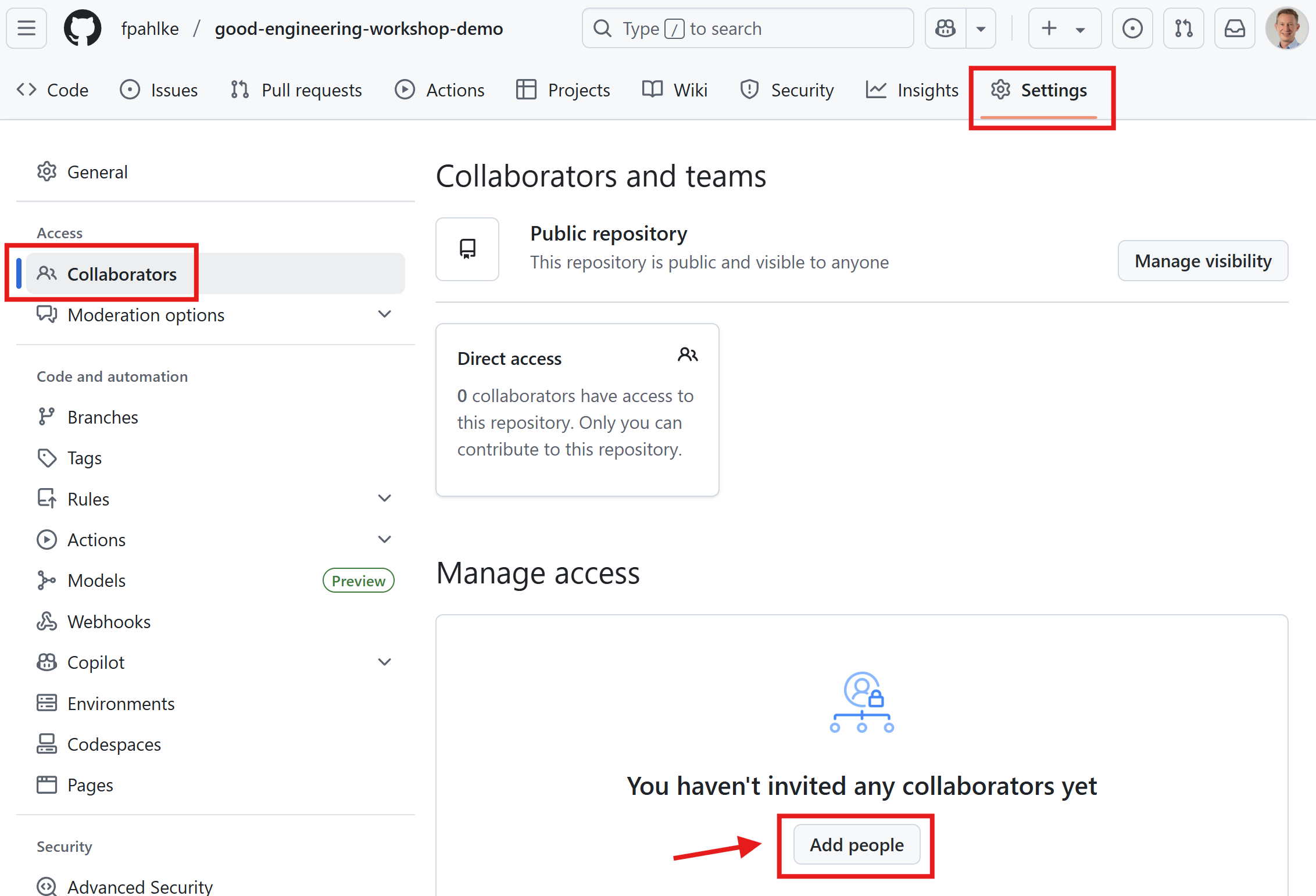
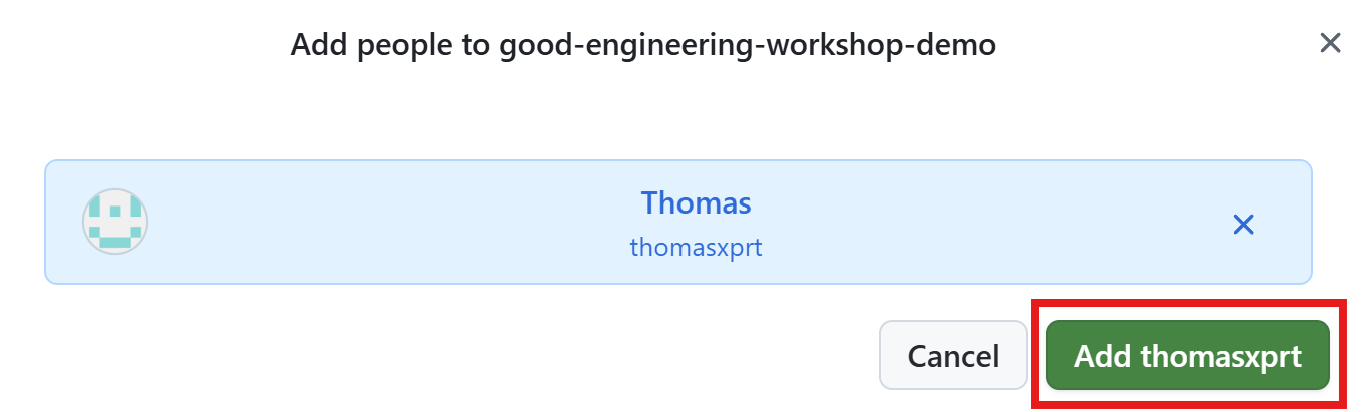
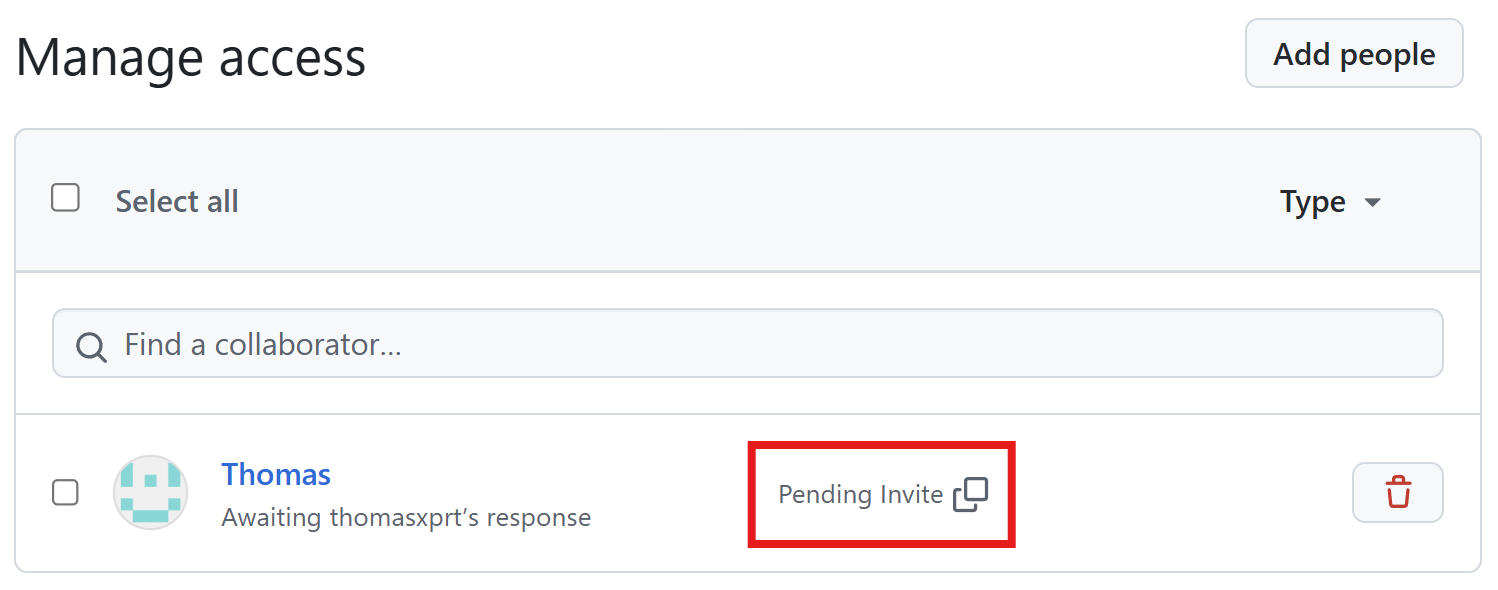
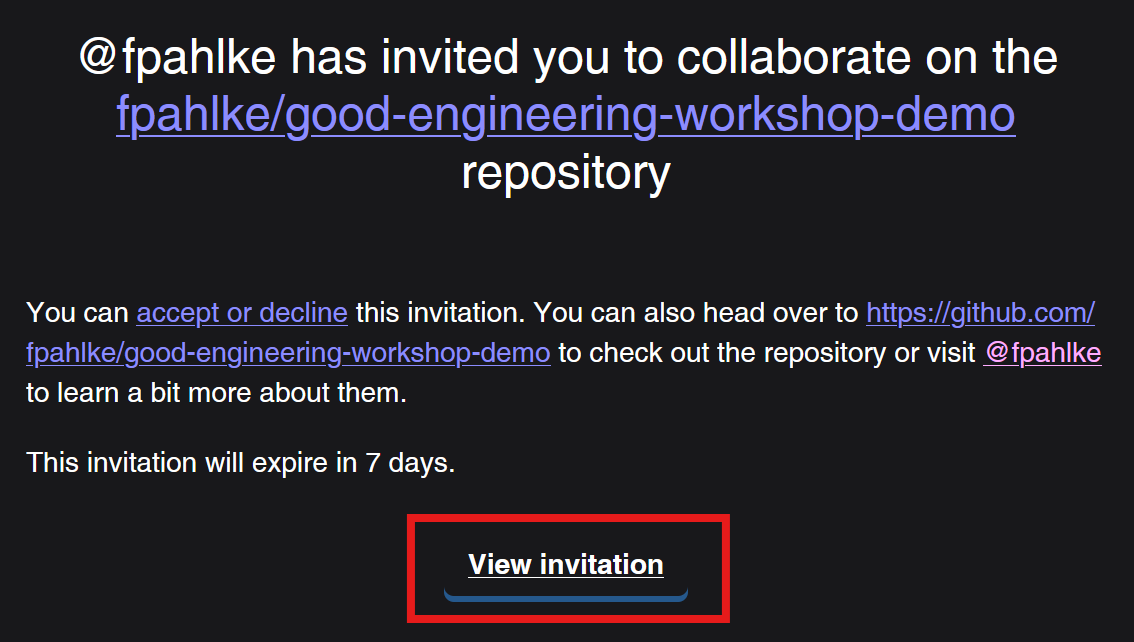
Add additional reviewers (cont’d)
Then add Thomas as reviewer.


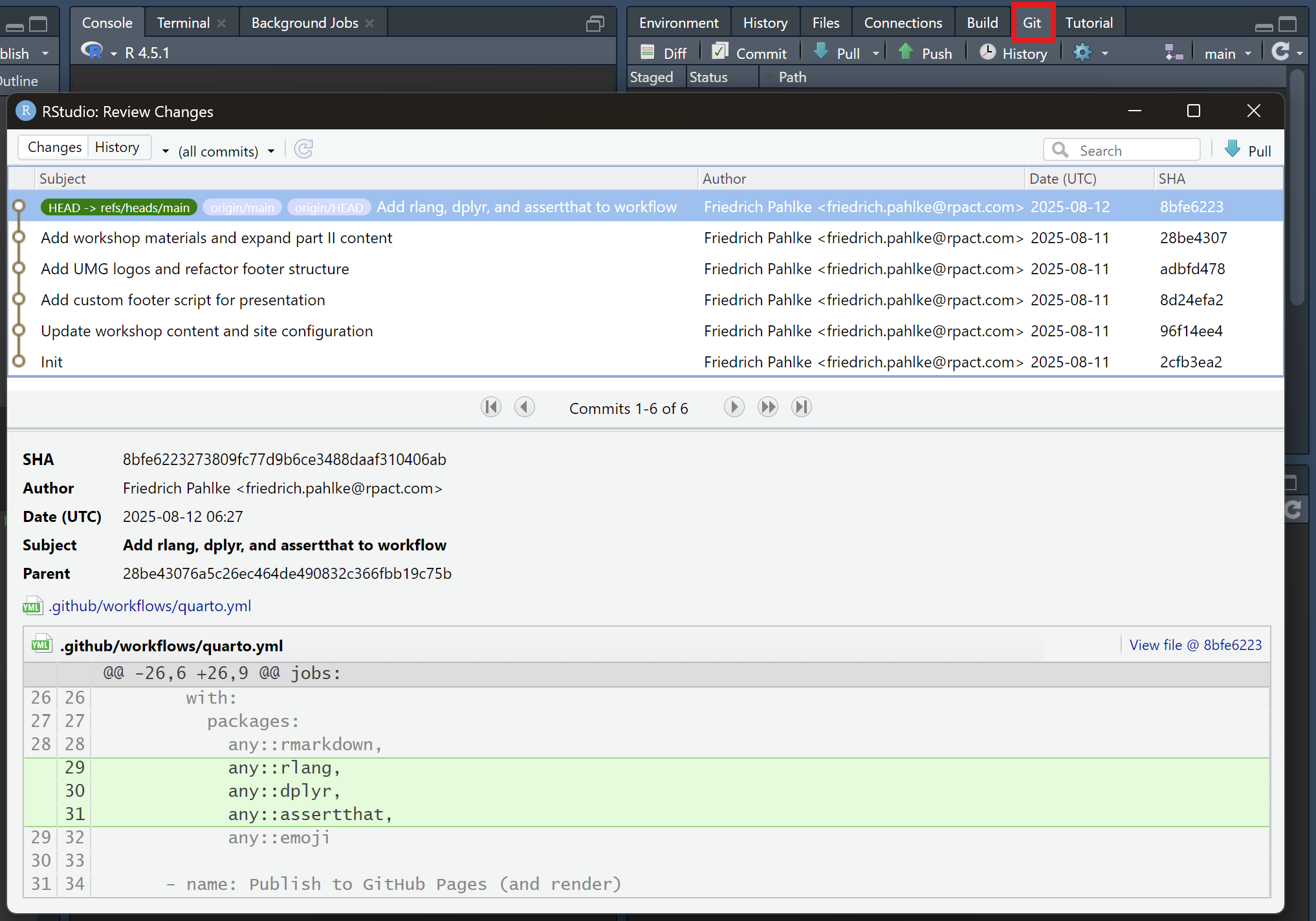
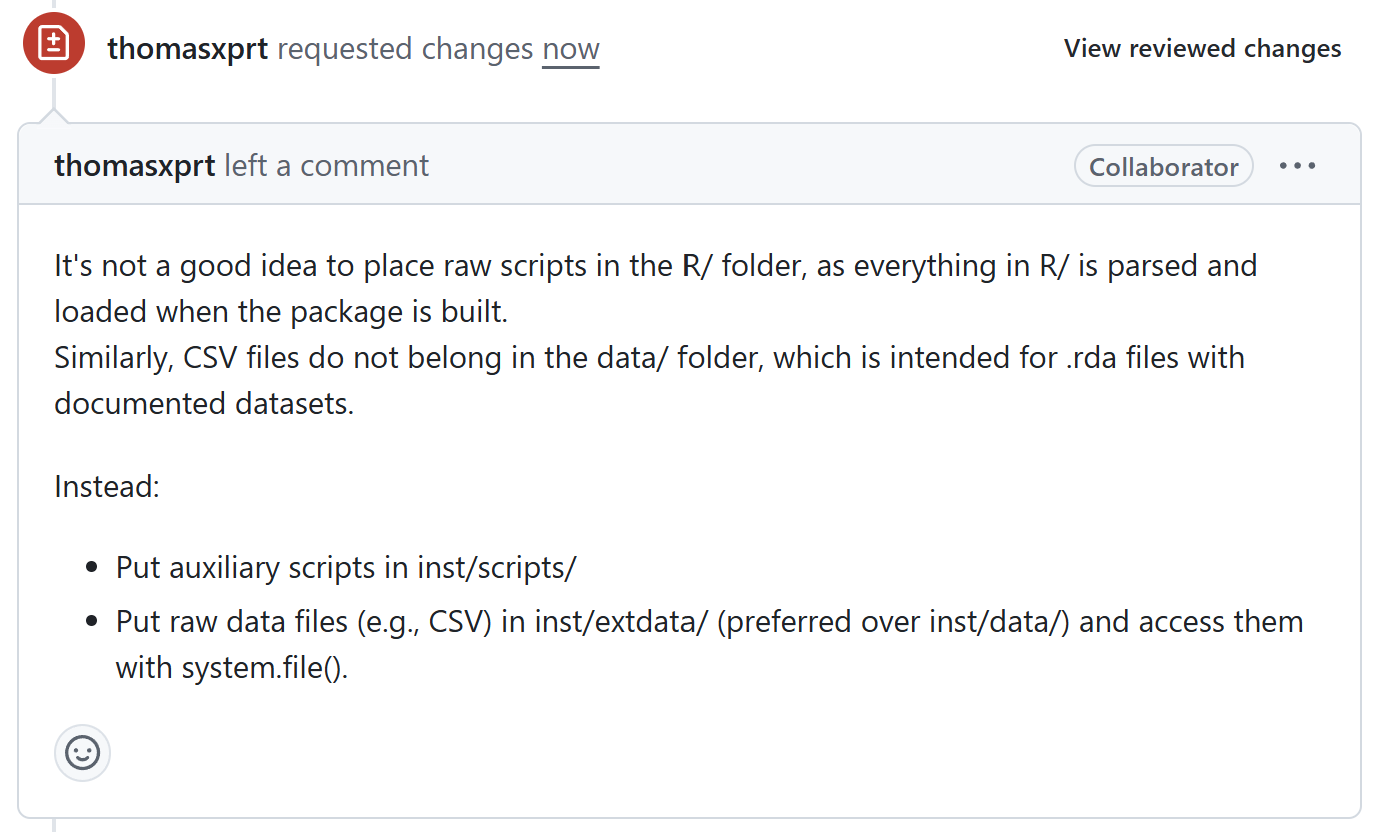
Thomas reviews the pull request
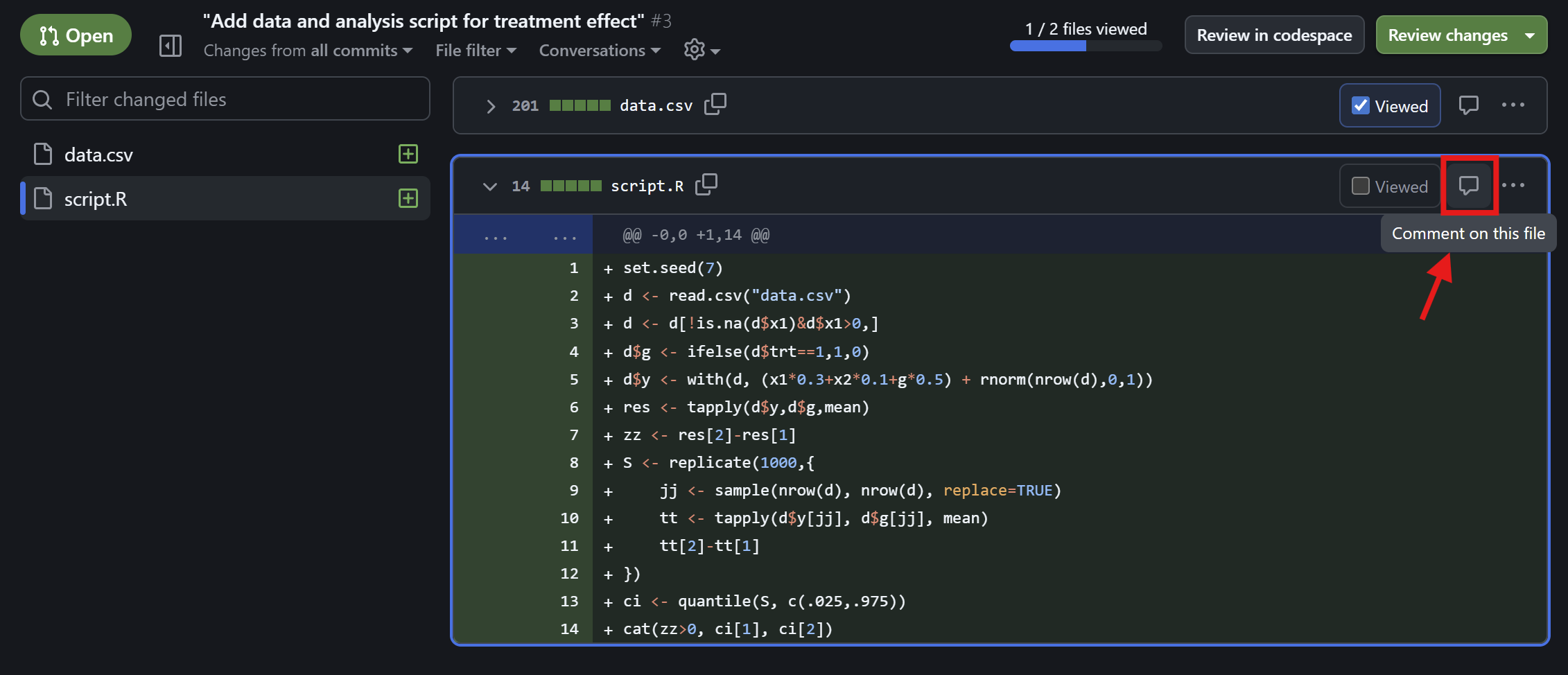

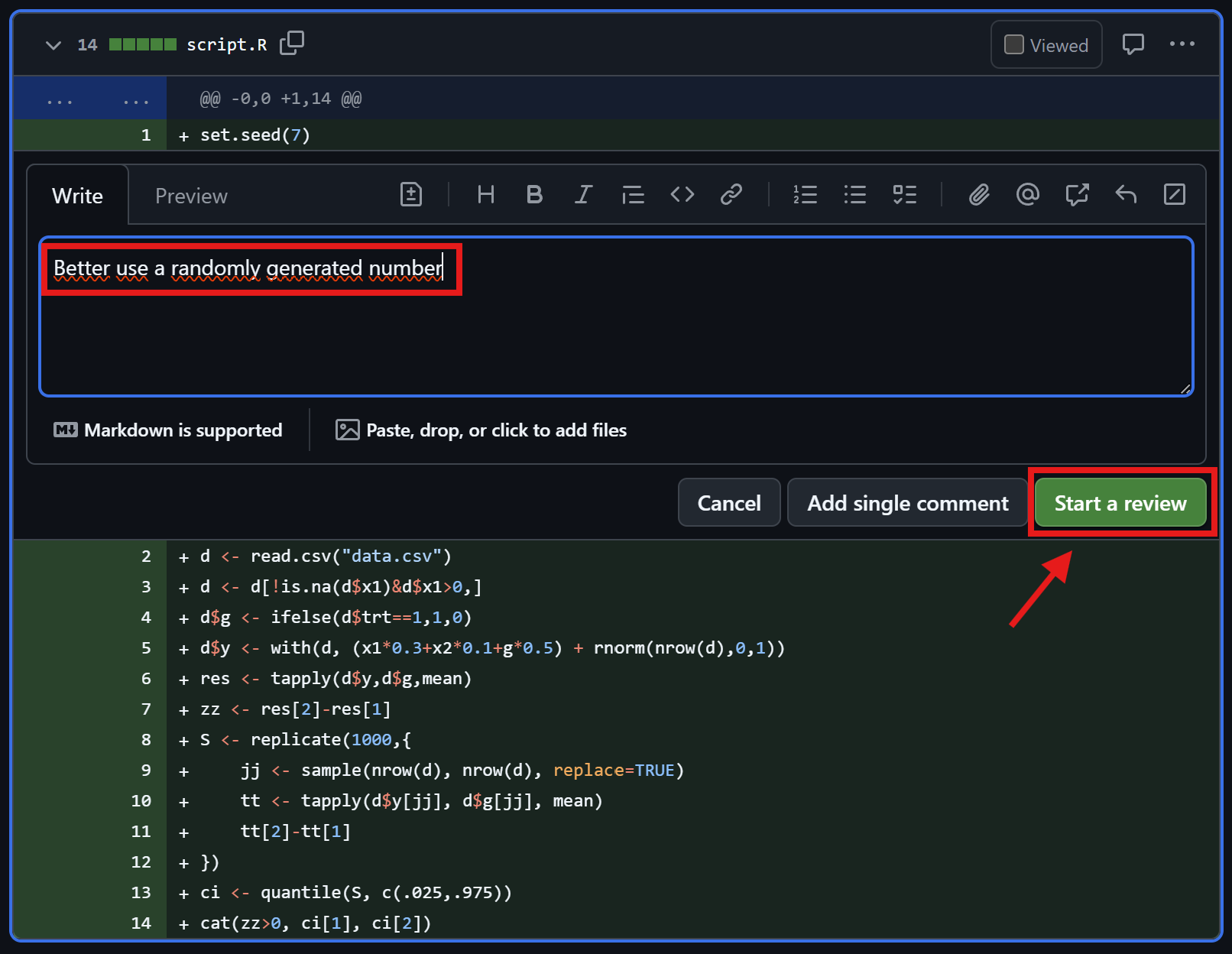
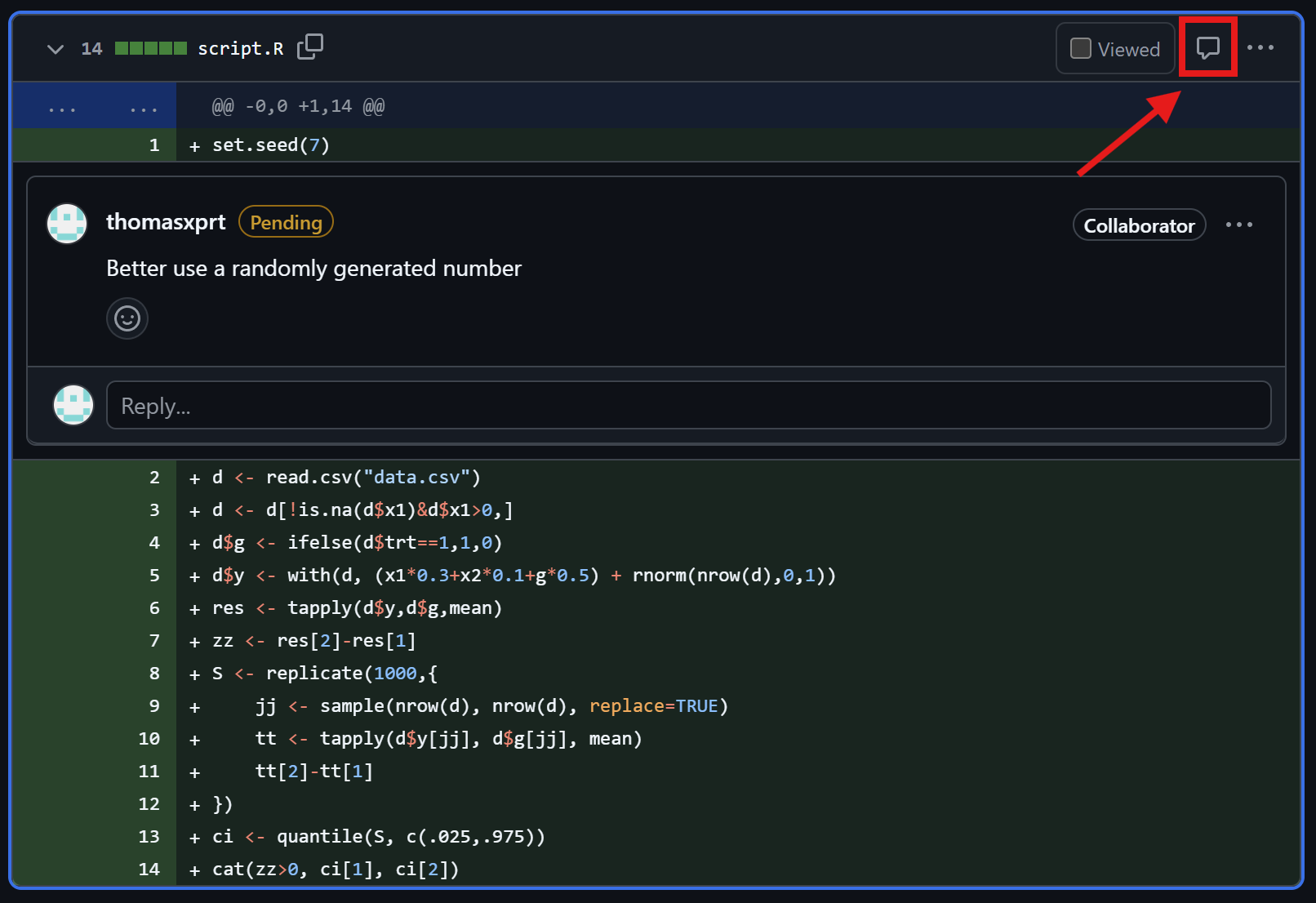
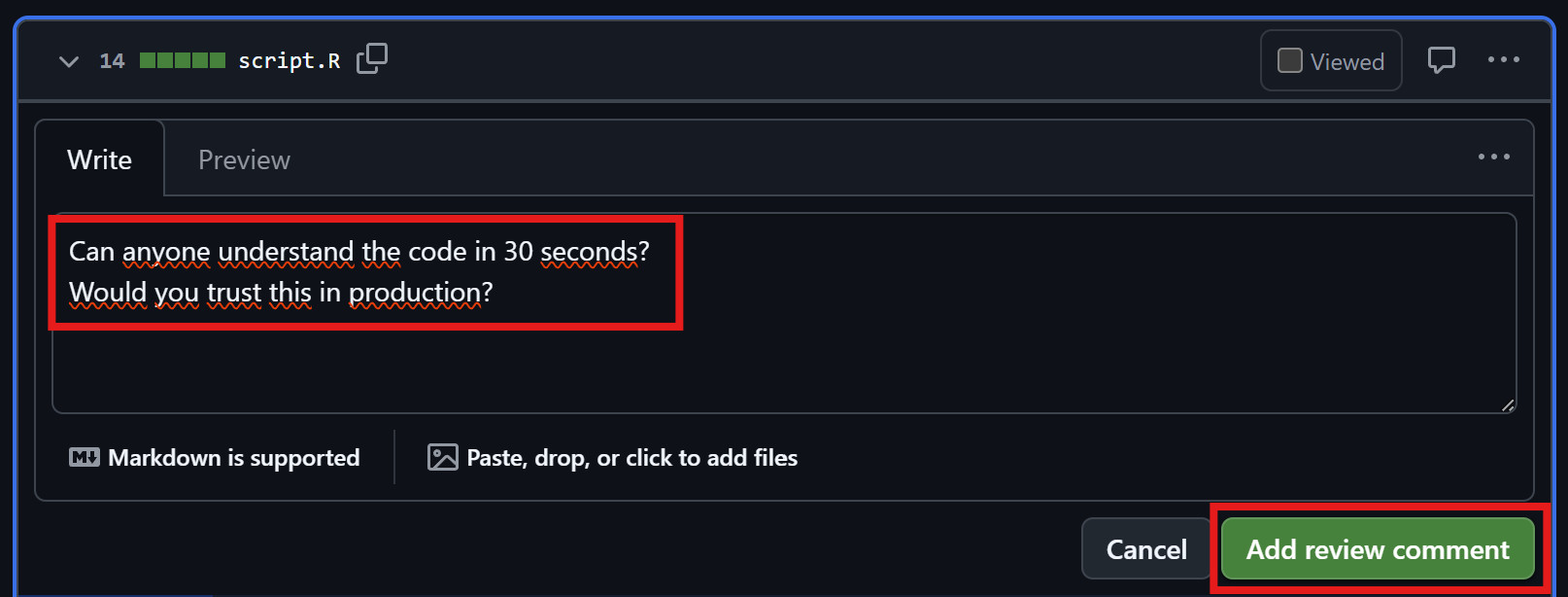
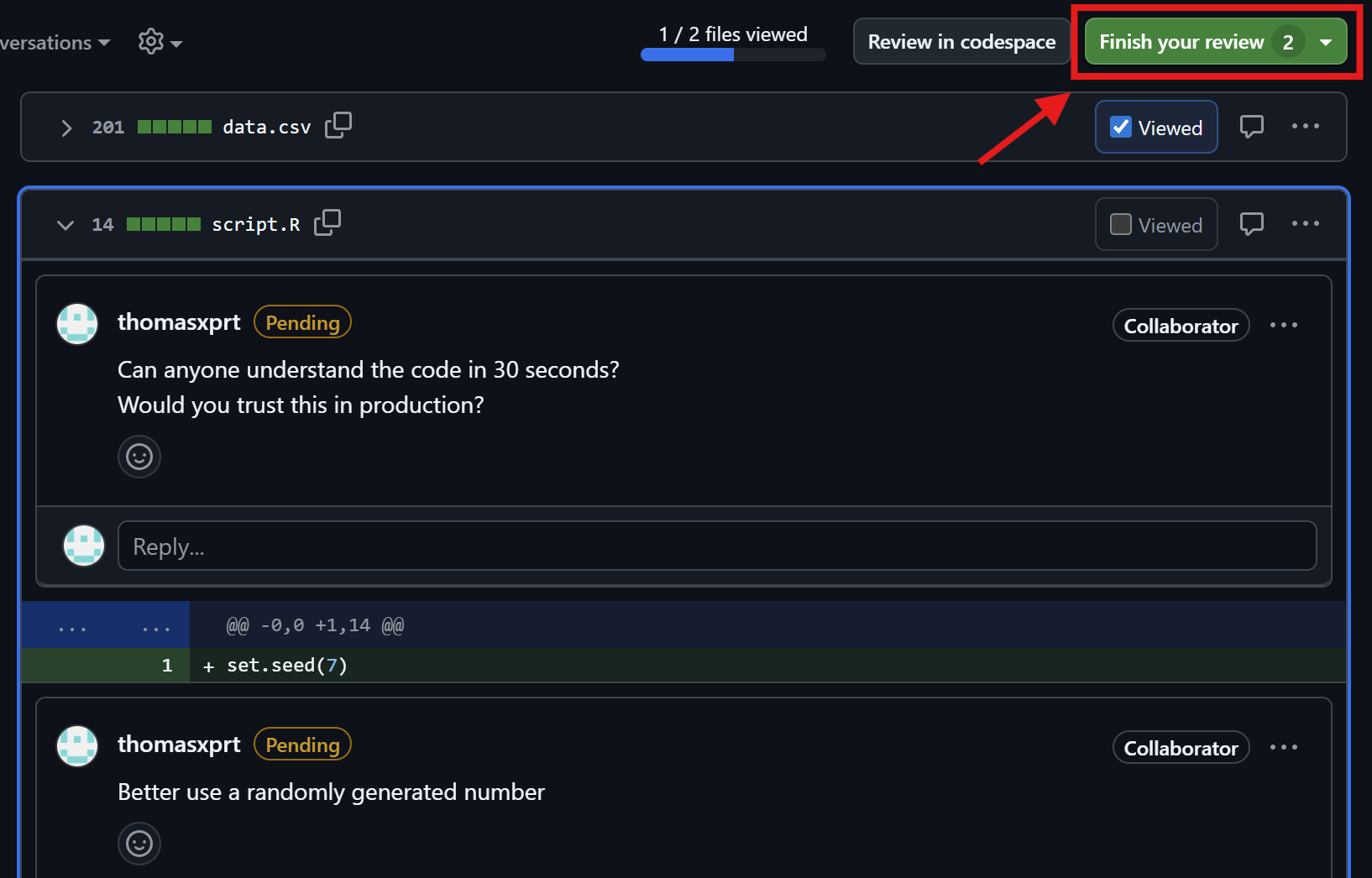
Friedrich checks the comments
Check reviewer comments
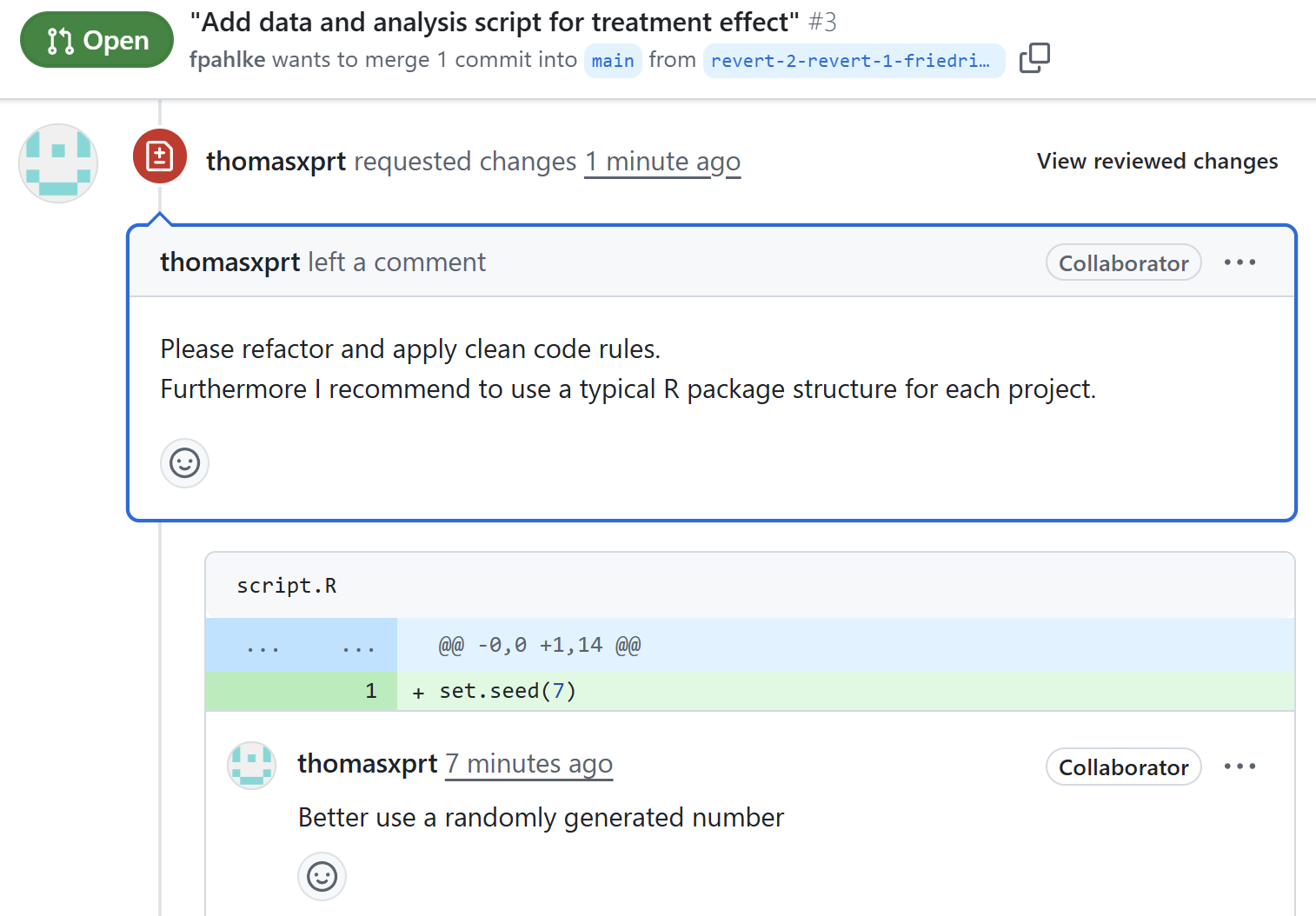
Friedrich fixes the issues
We use the usethis package to create a new R package structure that offers various advantages, even for projects that are not R package projects:
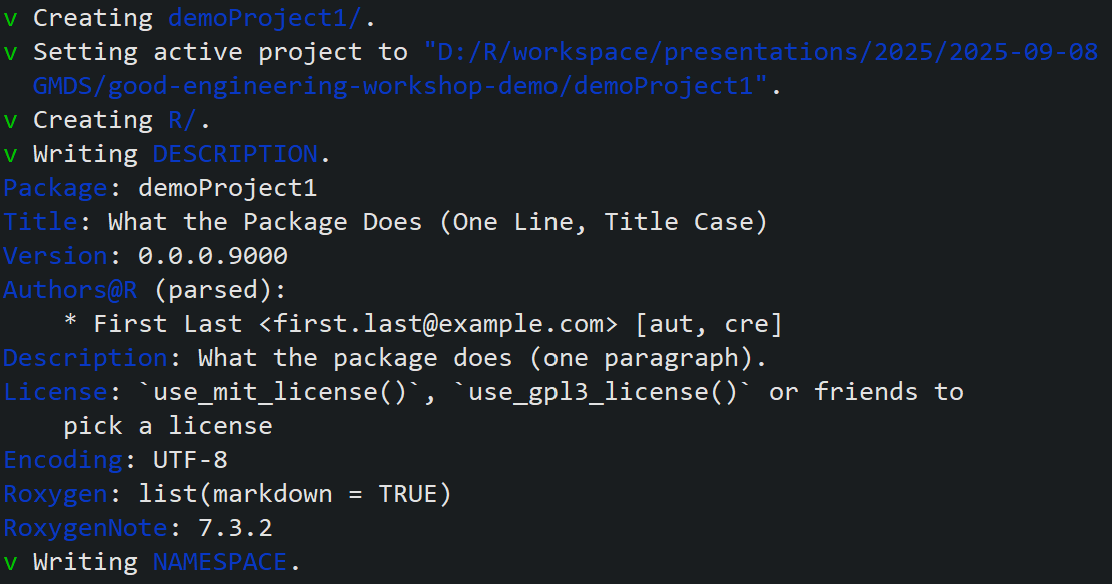
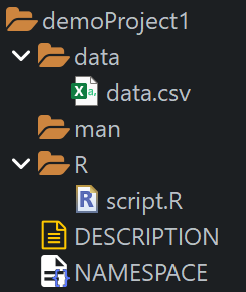
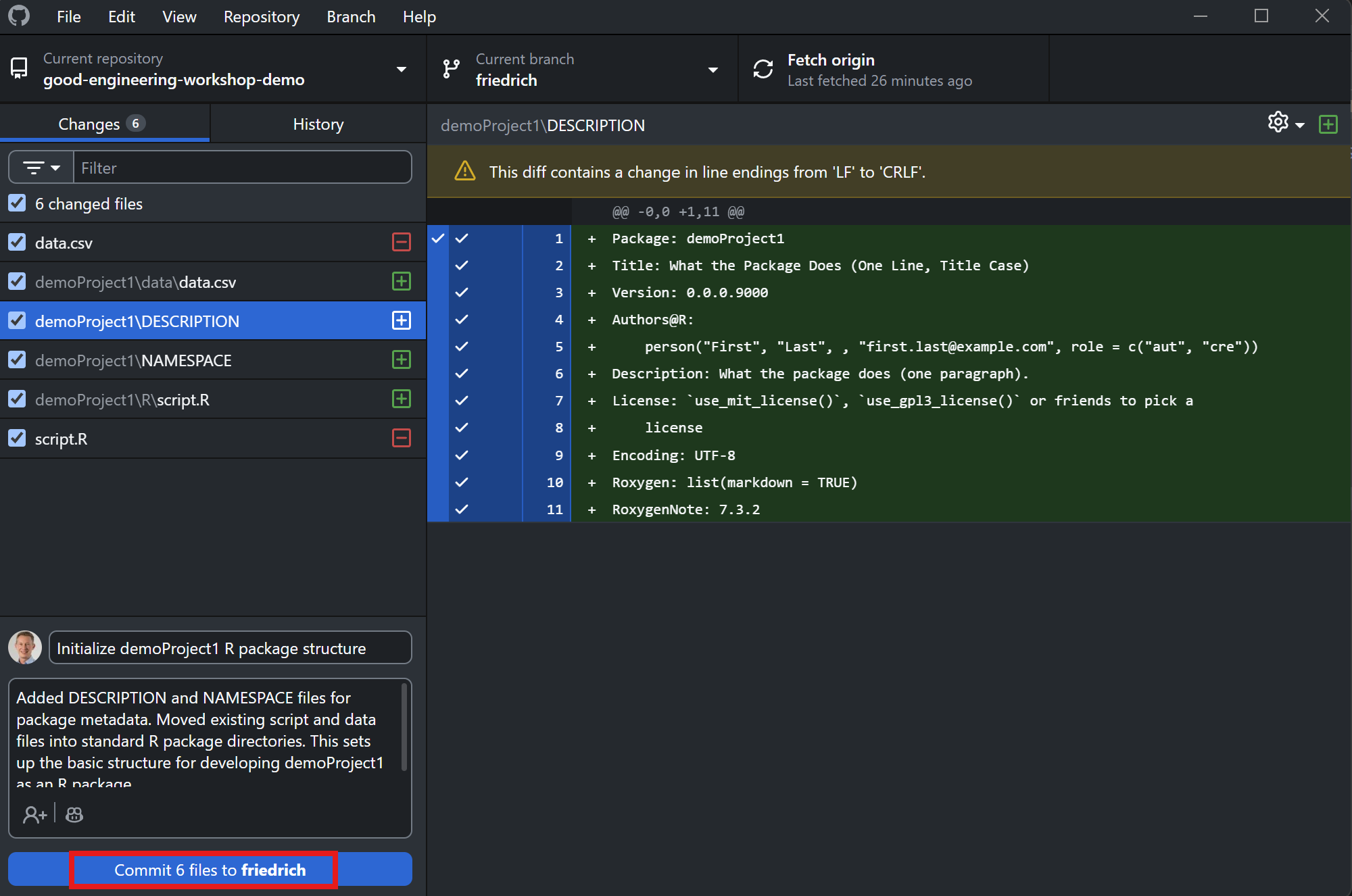
Friedrich commits the changes
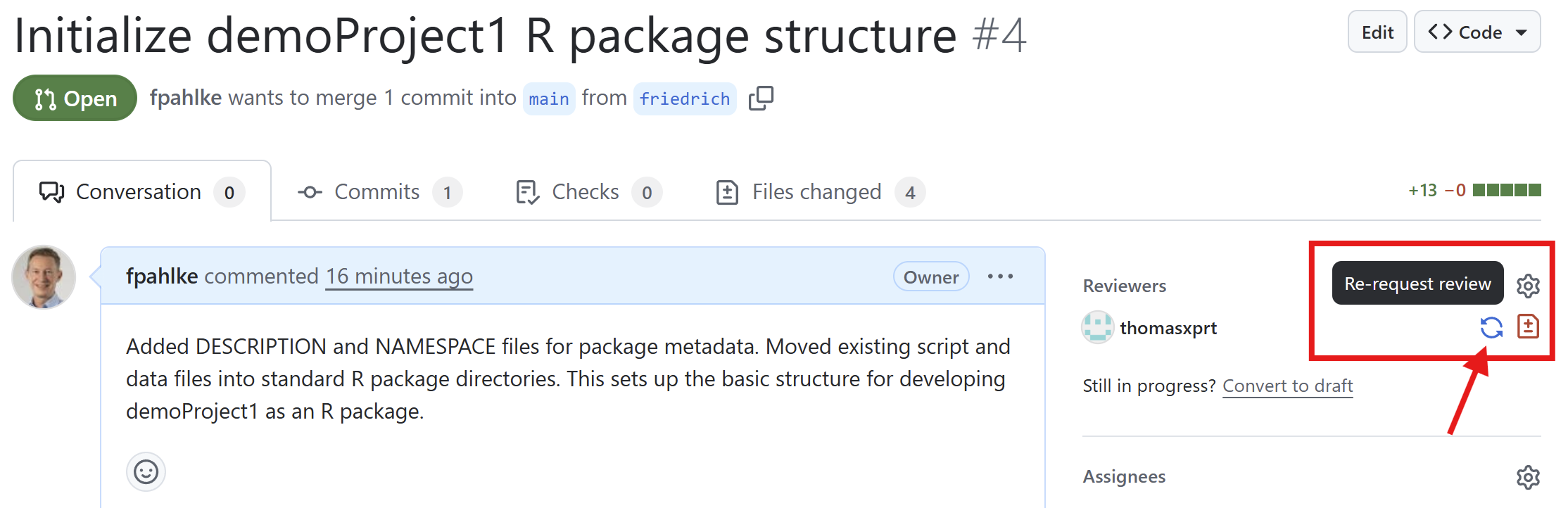
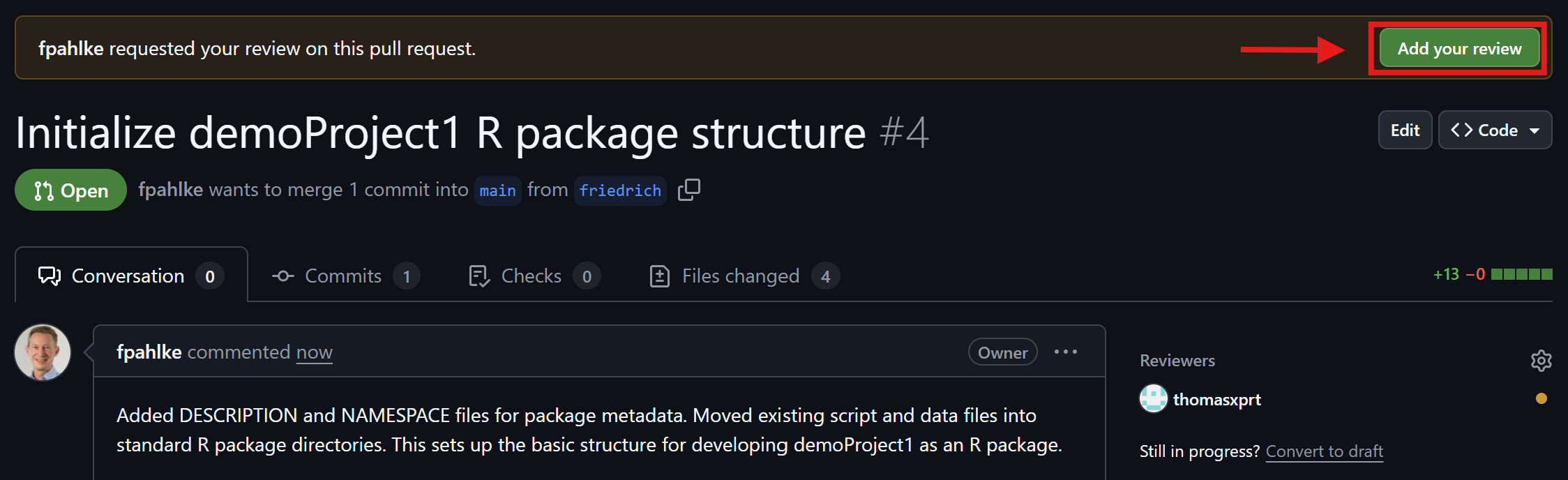
Thomas reviews the changes

Friedrich checks the comments (2nd round)
Check reviewer comments
Friedrich fixes the issues (2nd round)
- Put auxiliary scripts in inst/scripts/
- Put raw data files (e.g., CSV) in
inst/extdata/(preferred overinst/data/)
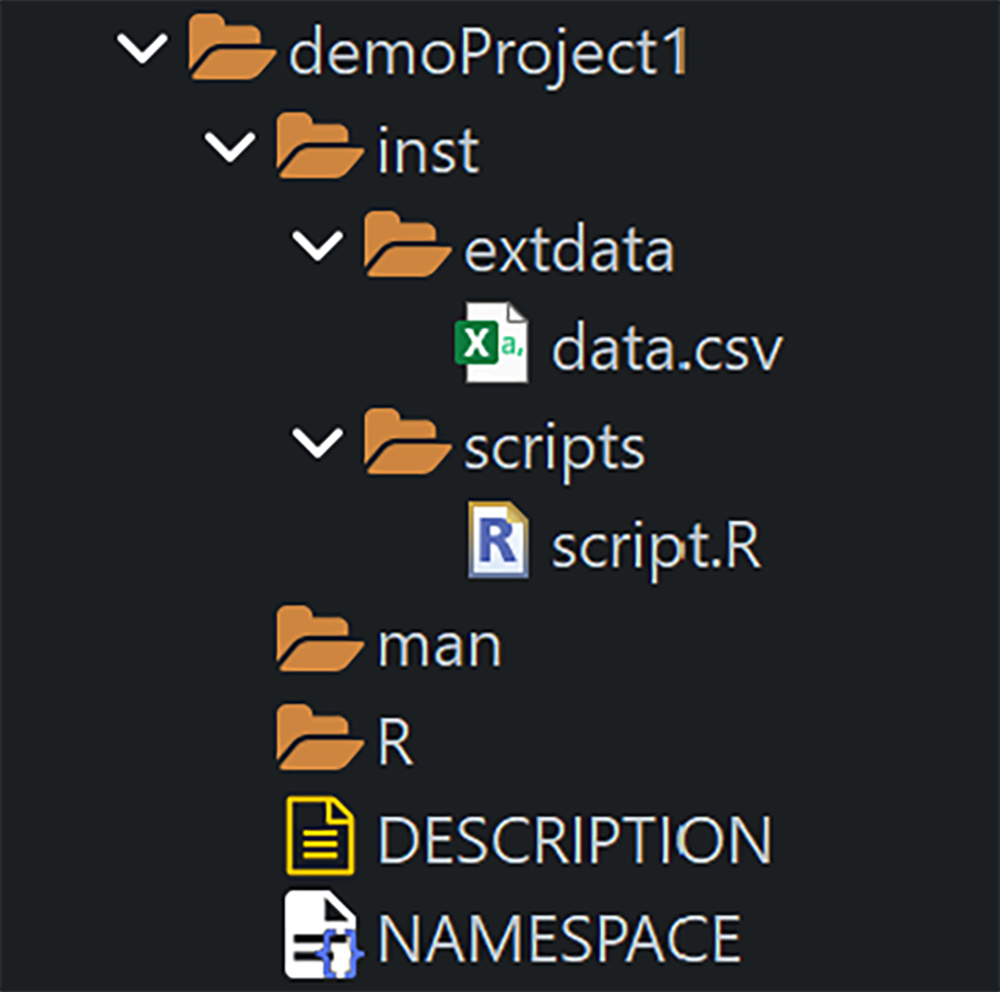
Restructure folders as requested by Thomas
Apply Clean Code Rules

Naming Conventions: snake_case vs camelCase
- Both are valid — choose based on your context & stay consistent
- snake_case: dominant in R packages developed by Posit, esp. tidyverse style guide
- camelCase: common in several R packages and Base R code, influenced by Java/C#
- Consistency is more important than style choice
Examples:
camelCase eats snake_case
Personal opinion: shorter words, i.e. less to write; as easy to read as snake_case

“Camels may eat snakes to obtain nutrients and cope with their harsh desert environment”
Source: afjrd.org/camels-eating-snakes
Testing & Debugging

Reproducibility

Summary

Q&A

Your scenarios, your code, …